Ethereum
Ethereum Hyperliquid
Hyperliquid Solana
Solana Arbitrum
Arbitrum BNB Smart Chain
BNB Smart Chain Base
Base Polygon
Polygon TRON
TRON Sui
Sui Robinhood
Robinhood



zkEVM and zkRollups Explained

As Ethereum became one of the most popular blockchains, its high adoption and use for currency exchanges and data interaction caused the network to reach its capacity (over 1 million transactions per day) and high demand for using it. This demand increased the gas fees that users are required to pay substantially.
The problem of Scalability
The popularly known blockchain trilemma involves being aware of providing a decentralized, secure and scalable network. However, to give decentralization and security, it must often sacrifice scalability.
At its current state, the Ethereum mainnet is only able to process 15 transactions per second. Usually, the network becomes congested, thus leading to slower transactions, increasing transaction fees, and becoming unusable for those who cannot afford them.
In this regard, the main goal of scalability is to increase transaction speed and throughput without sacrificing the other aspects of the trilemma: decentralization and security.
Sharding, layer two and zk rollups
The scalability problem is a known issue addressed by the Ethereum community and the foundation. A solution for this is sharding.
Commonly, sharding consists of splitting a database horizontally to spread its load. In the blockchain, this could reduce the congestion and increase the throughput by creating new chains known as “shards”. Also, validators will no longer be required to process all transactions on the network.
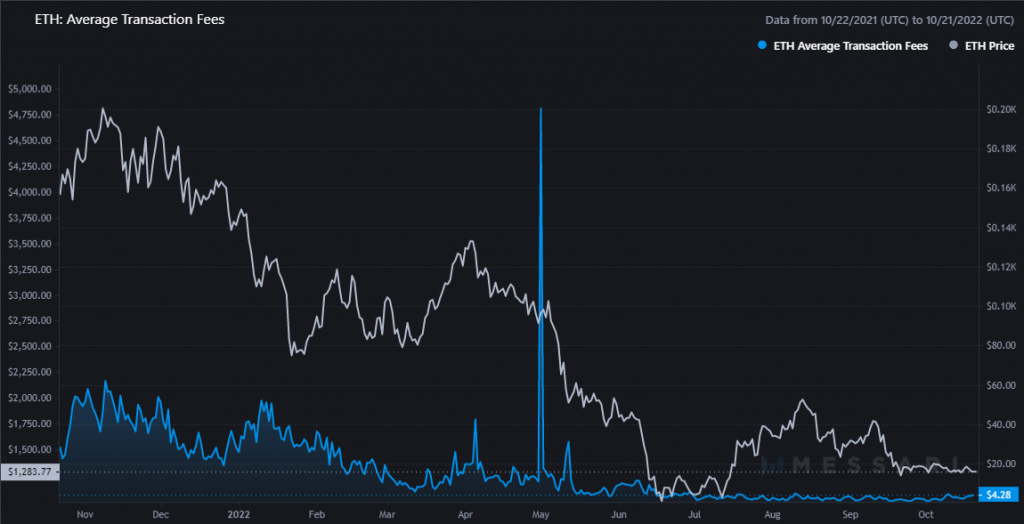
A layer two solution corresponds to a separate blockchain that takes advantage of Ethereum layer 1, extending its security and decentralization mechanisms. Usually, it communicates with the layer one solution submitting bundles of transactions as just one transaction. It takes the transaction load away from Ethereum and then submits proofs of the validated transactions back to layer 1. Learn more about layer two solutions and check how they work.
A rollup bundles many transactions that get verified outside layer one and submits them as a single transaction, thus distributing the load and fees across the transaction senders in the rollup. Currently, there are two approaches to rollups: optimistic and zero-knowledge. The main difference is how they validate the transaction submitted to layer one. As we will focus on zero knowledge, check this detailed explanation about optimistic rollups.
Zero-knowledge rollups and zkProofs
A zk-rollup bundles up to thousands of transactions in a batch that gets executed off-chain. Instead of an optimistic rollup, it just needs to post a summary of all transactions rather than all transaction data on-chain, making them more scalable. The verification of these transactions comes in the form of a validity proof, which is used to update the zk-state and consists of cryptographical and mathematical calculation. This state is maintained by smart contracts on the Ethereum mainnet.
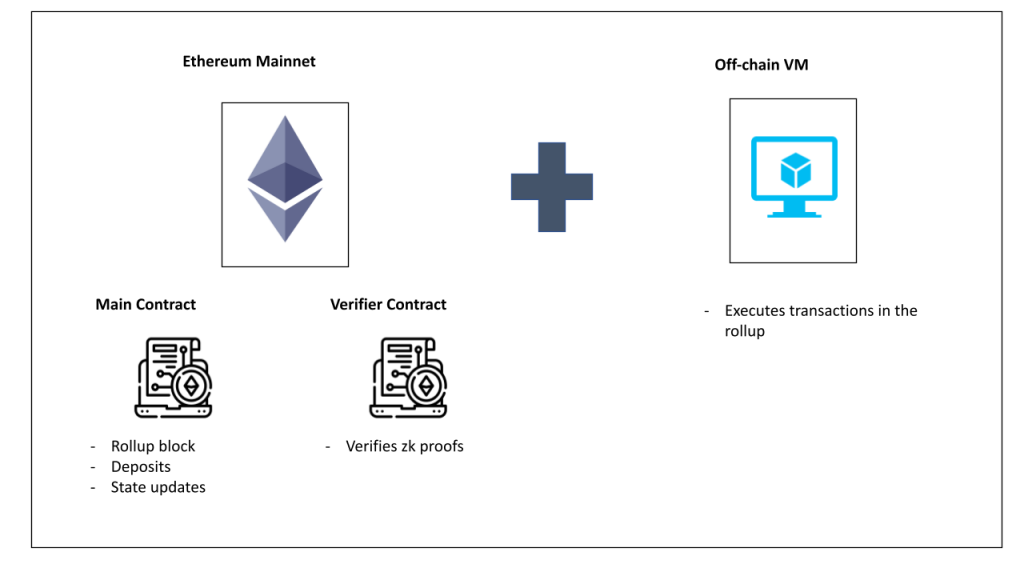
A zero-knowledge proof consists of a prover (in this case, the VM off-chain) who proves that a statement (a transaction or bundle of transactions) is valid without revealing the intrinsic method that verifies the information. So, for example, I can tell you I own an email address by sending an email notifying you I’m the guy sending it, but without revealing my credentials for anyone to check it.
zk-Snarks
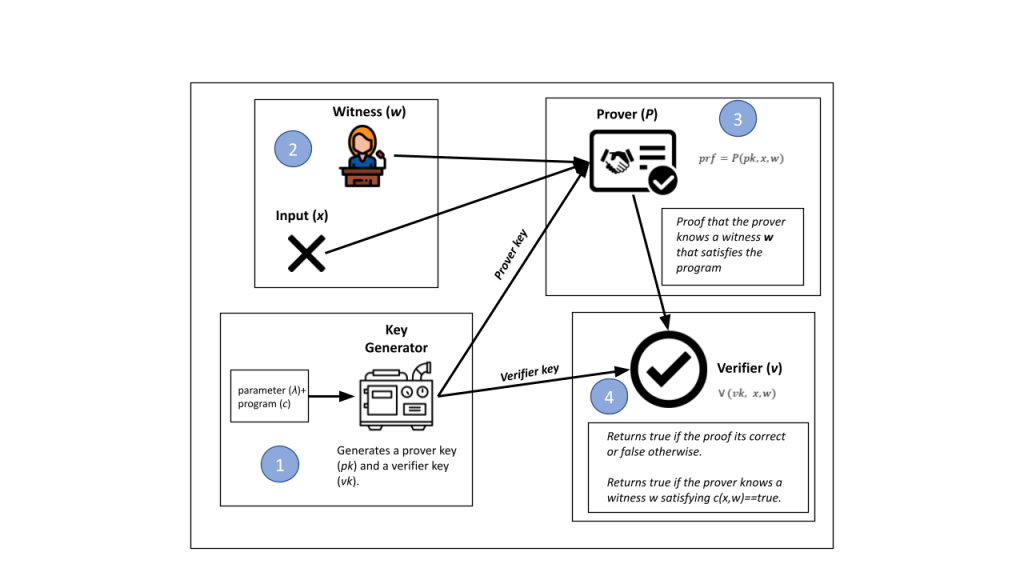
A zk-SNARK (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge) is a type of zero-knowledge proof that the proof itself is some data being verified without any interaction from the prover.
In short terms, it generates proof that some prover knows a witness that satisfies some program (i.e., A transaction or expression). For example, the following diagram illustrates the process of a simple zk-SNARK.
zero-knowledge EVM
The Ethereum Virtual Machine (EVM) wasn’t designed to work with zk-proof-computation. There’s no possibility of executing complex transactions like smart contracts with zk-proof-computation. A zkEVM is an attempt to build an EVM-compatible for rollups with zk-proofs while preserving the EVM codes and the knowledge derived from it so far.
The main drawback of trying to take advantage of EVM’s characteristics is that the EVM works as a stack of data and operations computed to transition into states. While a zkEVM would necessarily need to include the zk circuit to prove the correctness of transactions processed. The more straightforward approach considers adapting the low-level side of the virtual machine to have this circuit but losing the tools and infrastructure already provided for the EVM. Some methods believe this in much or lesser detail and the access from developers and builders to a new type of EVM that is more Ethereum-like and takes advantage of the zk-rollup scalability.
In this regard, Vitalik Buterin, founder of Ethereum, and teams from projects working on zkEVM development described five types of zkEVM equivalences with the normal EVM.
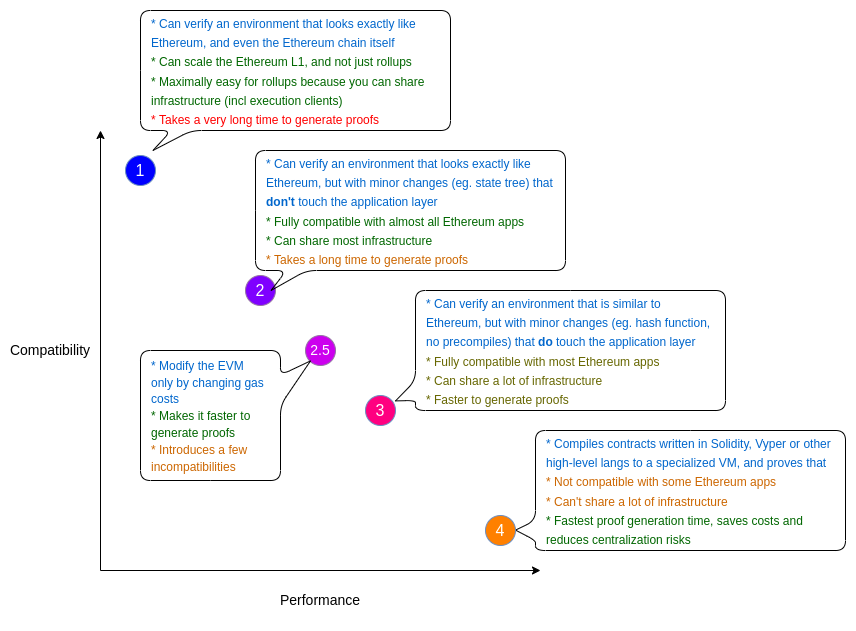
Type 1 zkEVM (Fully Ethereum-equivalent)
This type of zkEVMs does not change any part of the current Ethereum system. Therefore, its primary goal is to verify transactions, blocks, and data as they are being verified today.
Its effect is to allow execution clients to be used as-is to generate and process rollup blocks.
However, it can take many hours to produce current proofs times for Ethereum blocks.
Type 2 (fully EVM-equivalent)
Type 2 zkEVMs look exactly like Ethereum but differ in ways, such as data structures and the state tree. Its main goal is to be compatible with existing applications today but modify Ethereum in some minor ways to ease development and increase the speed of proof generation. However, it still needs to improve in the prover time.
One can solve some worst-case scenarios for proof generation by increasing gas costs on specific operations. However, it may break some applications and reduce the developer toolkit compatibility. This operation is addressed as Type 2.5 zkEVM.
Type 3 (almost EVM-equivalent)
Type 3 zkEVMs sacrifice some features from the EVM to improve proof times. These features often belong to the precompiles smart contracts of Ethereum contracts; also the way they handle contract code, the VM memory, and its stack.
In this case, most applications already built on the well-known EVM are considered to work, but some of them will need to be rewritten in case they are using some of the functionalities removed on this type of zkEVMs.
Type 4 (high-level-language equivalent)
This type of zkEVM compiles a smart contract code written in a high-level language (e.g., Solidity) into a ZK-SNARK-friendly language. This could drastically reduce the costs of building a zkEVM, but most of the tools already developed wouldn’t work (e.g., Debugging an EVM bytecode). Also, contracts wouldn’t have the same address as bytecodes could change on transpilation from language to language.
Conclusion
- Zk technology for blockchain is still early and has a lot of considerations, advantages, and drawbacks in its implementation. For example, proof validation uses circuits that can be very expensive to execute on each step of the computation of an EVM to transition to new states.
- Despite its complexity, researchers and the community have taken advantage of zk-rollups in a native way and are addressing the scalability problem of Ethereum’s original mechanisms. Hopefully, more projects like Polygon zkEVM, Scroll, zkSync, and Applied ZKP will get into the ecosystem and come up with a complete solution that doesn’t necessarily need to make a tradeoff between compatibility and speed.
- Discover how you can save thousands in infra costs every month with our unbeatable pricing on the most complete Web3 development platform.
- Input your workload and see how affordable Chainstack is compared to other RPC providers.
- Connect to Ethereum, Solana, BNB Smart Chain, Polygon, Arbitrum, Base, Hyperliquid, Robinhood Chain, Tempo, MegaETH, Monad, Plasma, Avalanche, Optimism, Scroll, Aptos, Cronos, Gnosis Chain, Kaia, Moonbeam, Celo, Aurora, TON, Ronin, and Bitcoin mainnet or testnets through an interface designed to help you get the job done.
- Fast access to blockchain archive data and gRPC streaming on Solana.
- To learn more about Chainstack, visit our Developer Portal or join our Telegram group.
- Connect your AI agent to Chainstack in seconds using Chainstack MCP — give Claude, Cursor, Codex, Gemini, and Windsurf live access to blockchain data, node management, and docs.
- Are you in need of testnet tokens? Request some from our faucets. Sepolia faucet, Base Sepolia faucet, Solana devnet faucet, Hoodi faucet, BNB faucet, zkSync faucet, Scroll faucet, Hyperliquid faucet, Monad faucet, Amoy faucet, Plasma faucet, TON faucet.
Have you already explored what you can achieve with Chainstack? Get started for free today.