Ethereum
Ethereum Solana
Solana Hyperliquid
Hyperliquid Arbitrum
Arbitrum Base
Base BNB Smart Chain
BNB Smart Chain Tempo
Tempo Avalanche
Avalanche Aptos
Aptos TRON
TRON Ronin
Ronin zkSync Era
zkSync Era Optimism
Optimism Sonic
Sonic Polygon
Polygon Unichain
Unichain Fantom
Fantom Gnosis Chain
Gnosis Chain Sui
Sui Avalanche Subnets
Avalanche Subnets Polygon CDK
Polygon CDK Starknet Appchains
Starknet Appchains zkSync Hyperchains
zkSync Hyperchains













Layer 1 vs Layer 2: Ethereum Infrastructure, RPC, and scaling
TL;DR
When comparing Layer 1 vs Layer 2 infrastructure in a real production environment, things rarely run on a single chain. You’re three chains deep into a deployment — Ethereum for settlement, Arbitrum for execution, Polygon PoS for the high-frequency stuff. Your RPC calls work fine in staging. In production, the same eth_getLogs behaves differently on each one — rate limits don’t match, WebSocket behavior diverges, and the custom namespaces you need for L2 aren’t on the provider you already pay for.
This is what multi-chain infrastructure actually looks like in 2026. Not a single chain, cleanly abstracted. A stack of layers with different security models, different finality semantics, and different operational failure modes — all of which you’re responsible for.
This guide walks through how each layer works, what running nodes on each one actually costs, and how to build RPC infrastructure that doesn’t become a liability at 2am.
Definitions and roles: Layer 1 vs Layer 2
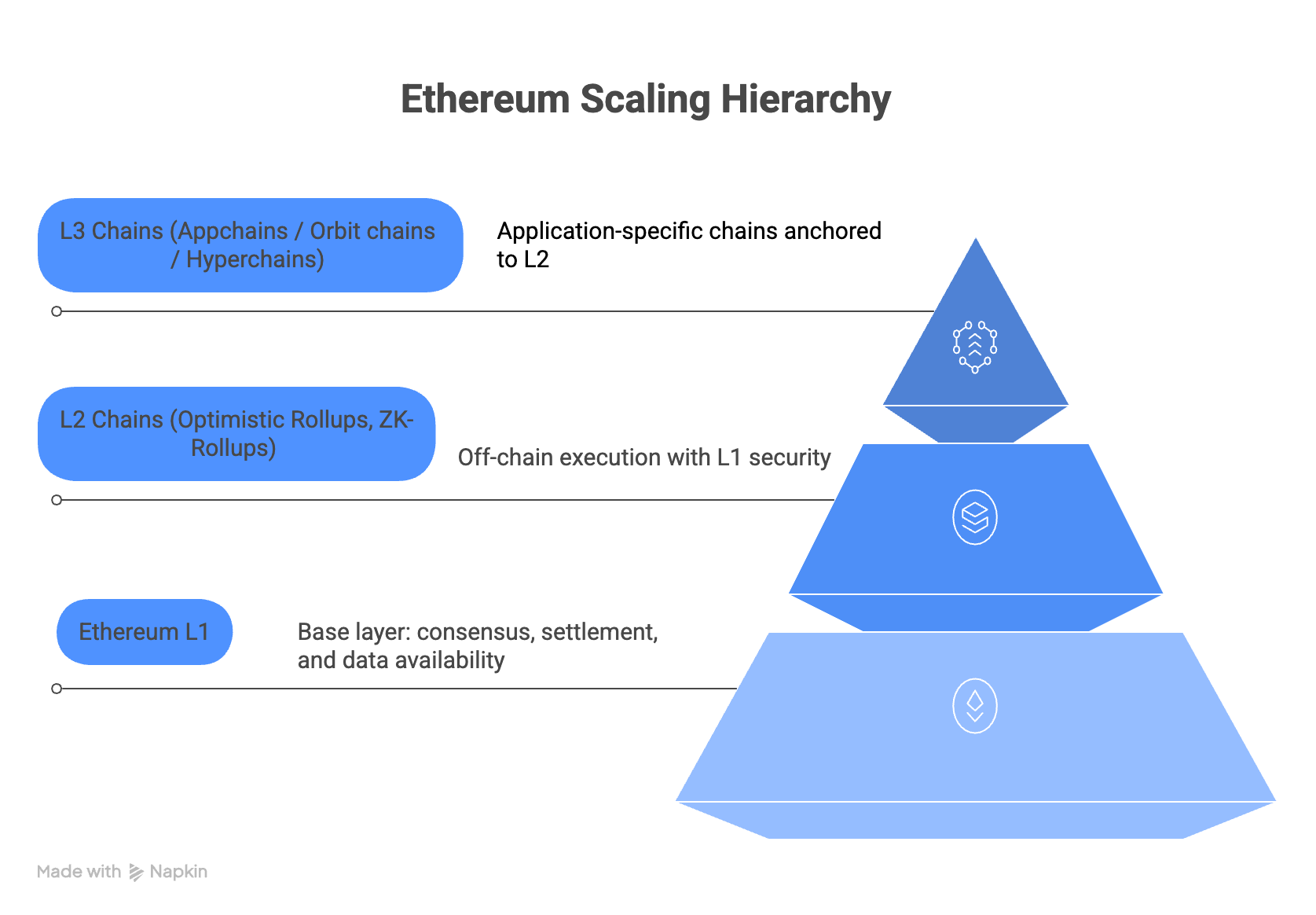
Ethereum L1 is the base blockchain (execution + consensus) secured by PoS validators. It defines canonical state and finality.
Layer 2 (L2) generally refers to rollups that settle to Ethereum and inherit its security assumptions to varying degrees:
- Optimistic Rollups (Optimism, Arbitrum): execute off-chain and post transaction data as calldata and/or blobs (post-Dencun) to L1. Anyone can challenge a fraudulent block within a dispute window (~1 week).
- ZK-Rollups (zkSync, StarkNet, Polygon zkEVM): execute off-chain and post a validity proof on L1. Transactions finalize once the proof verifies.
- Validiums (StarkEx): like ZK-rollups but data is kept off-chain, improving throughput at the cost of DA trust.
- Sidechains (Polygon PoS) are adjacent chains with independent validator security — not L1-secure. They connect to Ethereum via bridges or periodic checkpoints.
Layer 3 networks are typically application-specific chains built on top of Layer 2 rollups. They use Layer 2 for settlement and data availability while providing dedicated execution environments for specific applications such as gaming, trading, or social platforms. Examples include Arbitrum Orbit chains like ApeChain.
ℹ️ If you want to understand why Layer 2 exists in the first place, it comes down to the blockchain trilemma — the trade-off between decentralization, security, and scalability. We explain this in detail in our guide on solving the blockchain trilemma and Ethereum scaling solutions.
Layer summary
Note: All timing figures are indicative. Verify against official documentation.
| Layer | Consensus / Security | Data Availability | Finality | Examples |
|---|---|---|---|---|
| Ethereum L1 | PoS; highest security | On-chain (full state) | 12s slots; economic finality ~2 epochs (~12.8 min) | Ethereum mainnet |
| Optimistic L2 | Inherits L1 via fraud proofs; requires honest challengers | Ethereum blobs/calldata (post-Dencun: blobs preferred) | Instant “unsafe” on L2; OP Stack: unsafe/safe/finalized; 7-day delay for Standard Bridge withdrawals only | Optimism, Arbitrum |
| ZK-Rollup L2 | Validity proofs = L1 security | Ethereum calldata/blobs | Final once proof verified (seconds–minutes) | zkSync, StarkNet, Polygon zkEVM |
| Validium | Proof of integrity; weaker DA trust | Off-chain | As ZK-rollup for compute; weaker DA guarantees | StarkEx Validium |
| Sidechain (adjacent to L2) | Independent PoS; not L1-secure | On sidechain; L1 checkpoints | Fast internally; bridge/validators for L1 exit | Polygon PoS |
| L3 (Appchain) | Depends on parent L2 or DA layer | Parent L2 or DA chain | Similar to L2 parent | zkSync Hyperchains, Celestia rollups |
Node types across Layer 1 and Layer 2
Ethereum L1 node types
- Execution Client (Geth, Erigon, Besu): runs the EVM, executes transactions, manages state.
- Consensus Client (Teku, Lighthouse, Prysm): implements PoS beacon chain; handles block proposals and attestations.
- Validator: execution + consensus clients + signing keys. Must stake 32 ETH and maintain uptime.
- Full Node: stores recent state (~128 blocks). Hardware: 4+ cores, 16–32 GB RAM, 1–2+ TB NVMe SSD.
- Archive Node: stores all historical states (~13–15 TB on Geth). Required for deep historical queries.
- Light Client: headers only; verifies Merkle proofs. Low resource; planned for statelessness roadmap.
Optimistic L2 (Optimism, Arbitrum)
- Sequencer: orders L2 transactions, posts batches (calldata/blobs) to Ethereum, provides instant “unsafe” confirmations.
- Batch Poster / Batcher: compresses and submits transaction data to L1 to amortize gas costs.
- Verifier / Challenger: re-executes L2 transactions from posted data; submits fraud proofs on L1 during the dispute window if a bad batch is detected.
- Outbox Relayer: relays L2→L1 messages (e.g. withdrawal requests) back to Ethereum.
ZK-Rollup (zkSync, StarkNet, Polygon zkEVM)
- Sequencer: orders L2 transactions and posts data + proofs to L1.
- Prover: GPU-accelerated nodes that generate ZK proofs (STARK/SNARK) for each batch. Compute-intensive; may be centralized or sharded.
- Verifier (L1 contract): on-chain contract that checks the submitted proof and finalizes L2 state.
- Full Node (e.g. Juno for StarkNet): executes transactions and validates state transitions.
Sidechain (Polygon PoS)
- Heimdall Node: Cosmos/CometBFT-based validator; finalizes checkpoints and commits Merkle roots to Ethereum.
- Bor Node: Geth-based EVM execution client; produces PoS blocks in a rotating sprint/span schedule.
The hidden complexity of multi-chain RPC
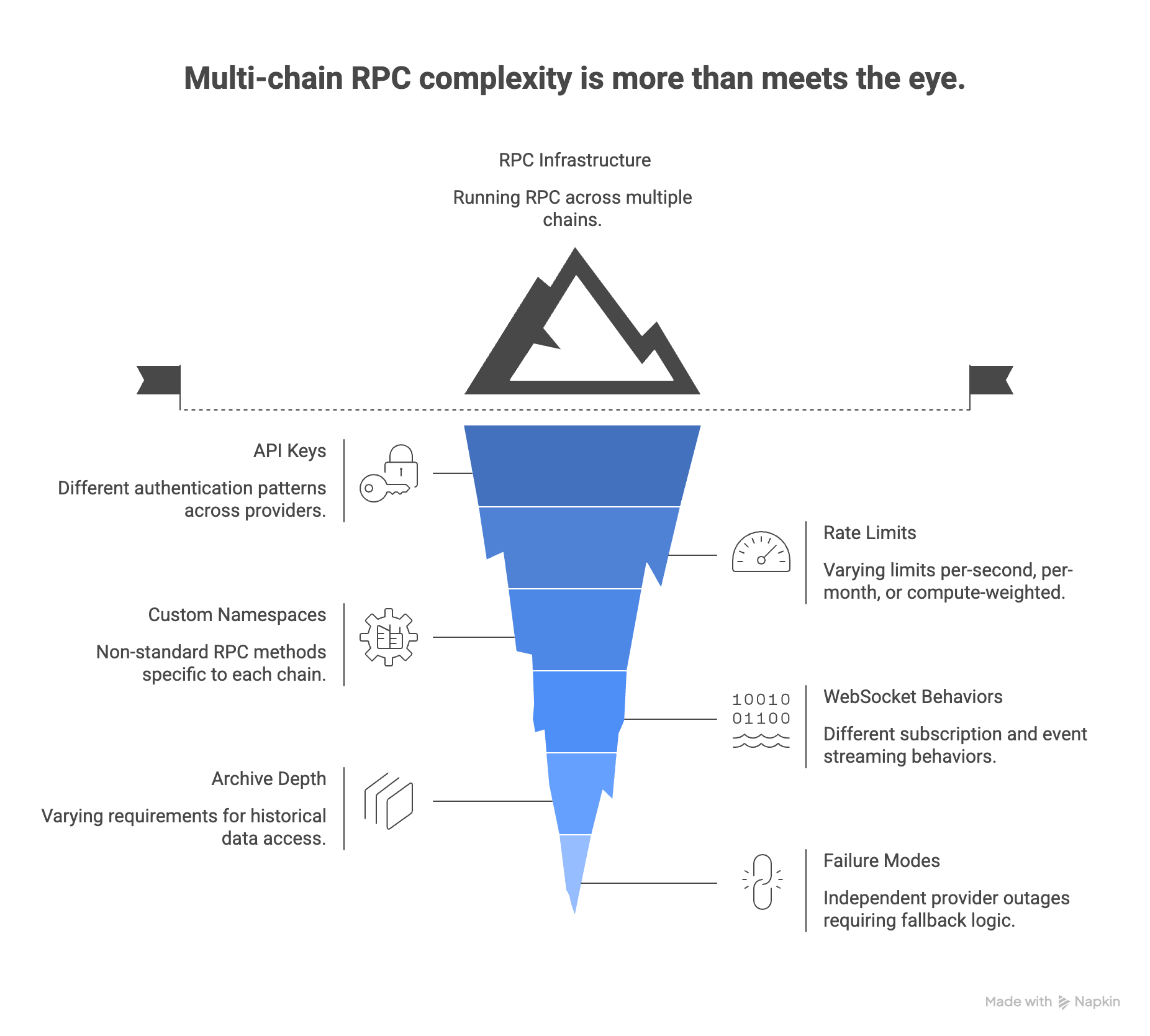
Running a single Ethereum node is a solved problem. Running RPC infrastructure across Ethereum, two L2s, and a sidechain is not — and the complexity doesn’t scale linearly.
Each chain adds:
- A different API key and authentication pattern — often across different providers
- Different rate limit behaviors — some are per-second, some are per-month, some are compute-unit weighted
- Custom namespaces that aren’t in the standard JSON-RPC spec (
optimism_*,arb_*, StarkNet’s own RPC spec) - Different WebSocket behaviors for subscriptions and event streaming
- Different archive depth requirements — some queries need deep history, others don’t
- Independent failure modes — a provider outage on one chain doesn’t affect others, but your fallback logic needs to know that
Most teams start by stitching together one provider per chain. It works until it doesn’t: rate limits hit at different times, billing arrives on separate invoices, and debugging a failed transaction means checking four different dashboards with four different log formats.
Layer 1 Layer 2 RPC Infrastructure
Applications interact with nodes via JSON-RPC (HTTP/WebSocket). Two primary approaches: self-hosted (trustless, no rate limits, requires ops) or hosted providers (managed, with free and paid tiers).
As of March 2026: All provider quotas and pricing change frequently. Figures below are indicative snapshots — always check official pricing pages before committing to a plan.
| Provider | Auth | Free Tier (snapshot) | Limit | Debug/Trace | Notes |
|---|---|---|---|---|---|
| Chainstack | API Key | ~3M requests/month (~25 RPS) | ~25 RPS (free tier) | Yes (archive included) | Request-based pricing (not CU-weighted); 70+ chains; 99.99%+ uptime SLA; SOC 2 Type II; dedicated nodes available |
| Infura | API Key | ~3M credits/day | ~500 credits/sec | Paid only (Team+) | Ethereum + many L2s; MetaMask-integrated |
| Alchemy | API Key | ~30M CU/month | ~500 CUPS | Paid only | Compute Units pricing; rich NFT/DeFi APIs; GraphQL |
| QuickNode | API Key | ~100k calls/day | ~1.2 req/sec | Paid plans | Fast endpoint creation; archive on paid plans; SOC 2 Type II |
| Ankr | API Key | ~1,800 req/min across all EVM chains | ~30 req/sec (all endpoints) | Paid/advanced | 60+ chains; pay-as-you-go model |
Running across multiple chains in production? Chainstack gives you archive access, WebSocket support, and dedicated nodes across Ethereum, Arbitrum, Polygon, StarkNet, and 70+ other networks — with request-based pricing that doesn’t penalize you for complex queries.
All providers support core Ethereum methods (eth_call, eth_sendRawTransaction, eth_getLogs, etc.). L2 networks add custom namespaces: Optimism’s optimism_*, Arbitrum’s arb_*, StarkNet’s own spec. Advanced methods (debug_traceTransaction, trace_block) are typically restricted to paid tiers. Infura, Alchemy, QuickNode, Ankr, and Chainstack all support WebSockets for eth_subscribe.
Scaling architecture and Data Availability
Understanding Layer 1 vs Layer 2 architecture is essential when designing multi-chain infrastructure, because execution, data availability, and settlement happen on different layers.
Optimistic vs ZK Rollups
Both move execution off-chain but differ in trust model. Optimistic rollups avoid heavy proofs (lower compute cost) but require a fraud-proof window and active challengers. ZK rollups prove every batch cryptographically — higher prover cost but instant settlement once the proof is verified on L1.
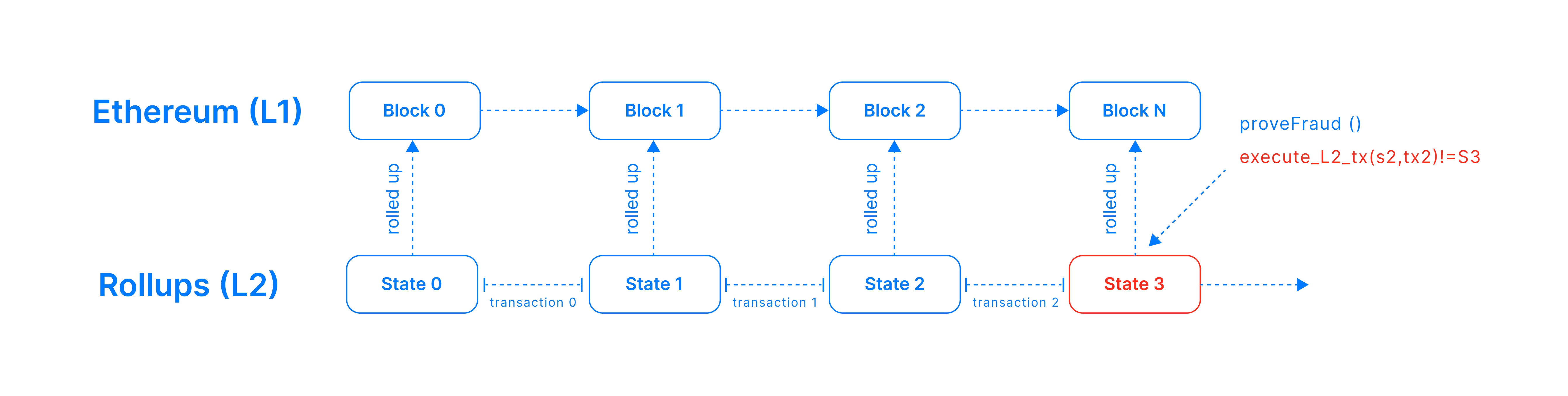
Sequencer centralization and failure modes
Many L2s still depend on a centralized or permissioned sequencer. This improves user experience by providing fast confirmations and predictable ordering, but it also introduces a practical infrastructure risk: execution may feel decentralized at the settlement layer while still depending operationally on a small number of sequencing actors.
For infrastructure teams, the key question is not only how an L2 settles to Ethereum, but what happens when the sequencer degrades, censors, or goes offline. Important failure-mode questions include whether the system supports forced inclusion from L1, whether users can still reconstruct state from posted data, whether withdrawals remain safe during downtime, and how long the application can tolerate sequencer interruption before UX or treasury flows are affected.
This matters because many products experience the sequencer as the chain. If the sequencer stalls, users do not care that final settlement is ultimately protected by Ethereum—they care that transactions stop confirming, APIs stop updating, and withdrawals or cross-chain operations become delayed. In practice, sequencer design is one of the most important operational differences between L2 stacks.
Data Availability (DA) Layers
All rollups need DA so anyone can reconstruct L2 state. Most post to Ethereum (as calldata or blobs post-Dencun). Alternative approaches:
- Ethereum DA: Used by Arbitrum, Optimism, StarkNet. As secure as Ethereum itself.
- DA committees: Arbitrum Nova uses an AnyTrust model with a Data Availability Committee (DAC) — distinct from OP Stack or Celestia-based designs.
- External DA layers: Celestia uses light-node sampling to probabilistically prove data availability, enabling modular, high-throughput rollup stacks.
EIP-4844 and the Rollup-Centric Roadmap
EIP-4844 (blob transactions, “proto-danksharding”) activated in the Dencun upgrade on March 13, 2024, introducing cheaper data blobs for L2s. The Ethereum roadmap treats rollups as the primary execution layer, with Ethereum serving as consensus + DA. Future data sharding will further expand capacity.
Performance trade-offs
| Attribute | Ethereum L1 | Optimistic L2 | ZK-Rollup L2 | Polygon PoS (Sidechain) |
|---|---|---|---|---|
| Security | Highest (thousands of PoS validators) | L1 security via fraud proofs; requires honest challengers | Cryptographic L1 security via validity proofs | Own ~100 validators; not L1-secure |
| TPS | ~15 TPS | Hundreds–thousands (~2,000 expected) | Thousands+ (~9,000 StarkNet; ~3,000 zkSync) | ~65–100 TPS |
| Finality | ~2 epochs (~12.8 min) | Instant “unsafe”; 7-day delay for Standard Bridge withdrawals | Seconds–minutes after proof on L1 | ~10s; bridge takes checkpoint intervals |
| User Fees | High (EIP-1559) | ~1/20th of L1 | ~1c–few cents (target) | ~1c; bridging adds cost |
| Decentralization | Thousands of validators; many client implementations | Sequencer centralized today; decentralization planned | Sequencer centralized; multi-sequencer in R&D | ~100 elected validators |
Infrastructure and hardware
| Role | CPU | RAM | Storage | Notes |
|---|---|---|---|---|
| L1 Full Node | 4+ cores | 16–32 GB | ~1–2 TB NVMe | Pruned; snap sync |
| L1 Archive Node | 4+ cores | 32+ GB | ~13–15 TB SSD | All historical states |
| L1 Validator | 4+ cores | 32+ GB | ~1–2 TB NVMe | 24/7 uptime; HSM for keys |
| OP Stack Full Node | 4+ cores | 16–32 GB | ~700 GB+ NVMe | Growing ~100 GB/6mo |
| Arbitrum Full Node | 4+ cores | 16–32 GB | ~500 GB+ NVMe | ArbOS; growing |
| StarkNet Node (Juno) | 4+ cores | 32+ GB | ~300 GB+ NVMe | +100 GB/yr growth |
| ZK Prover Cluster | 8+ cores | 64+ GB | 2+ TB NVMe | GPU recommended |
| Polygon PoS (Bor) | 4 cores | 16+ GB | ~1 TB SSD | Geth-based |
| Polygon (Heimdall) | 2–4 cores | 4–8 GB | Moderate SSD | Cosmos-based |
What does this actually cost? A worked example
Say you’re running a production DeFi application — a DEX aggregator routing orders across Ethereum mainnet, Arbitrum, and Polygon PoS. Your traffic profile looks roughly like this:
- ~40,000
eth_callrequests/day (price checks, quote simulation) - ~8,000
eth_getLogsrequests/day (event indexing) - ~2,000
eth_sendRawTransactionrequests/day (order submission) - WebSocket subscriptions for mempool and block events on all three chains
- Occasional
debug_traceTransactioncalls for support and debugging
On free tiers alone: You’ll hit rate limits within hours on any single provider. Free tiers are sized for development, not production — 30M compute units/month on Alchemy sounds large until eth_getLogs costs 75 CUs per call and you’re running 8,000 of them daily across three chains.
On a mid-tier paid plan (~$49–99/month): Workable for early production, but you’ll need to manage one provider per chain carefully, implement retry/backoff, and accept that debug_traceTransaction may not be available.
Self-hosted full nodes (~$500–700/month in cloud compute per node): Full control, no rate limits, archive access included. The cost is real, but so is the operational overhead — sync management, disk growth monitoring, client upgrades, and the on-call rotation that comes with it.
The practical middle ground for most teams: A dedicated node provider with archive access and WebSocket support on your highest-traffic chain (usually Ethereum mainnet), free or low-tier endpoints for secondary chains during early growth, and a fallback provider array so a single outage doesn’t become a user-facing incident.
Rule of thumb: Budget $150–300/month for serious production RPC across 2–3 chains before you need dedicated nodes. Model your actual call volume against provider pricing pages — CU-weighted pricing (Alchemy) and request-based pricing (Chainstack) behave very differently at scale.
Operational checklists
Node deployment
- Choose clients: Geth/Erigon + Teku/Lighthouse for L1; op-node + op-geth for Optimism; Arbitrum Nitro (ArbOS) for Arbitrum; Juno for StarkNet; Bor + Heimdall for Polygon.
- Provision hardware per the table above. Ensure >100 Mbps internet.
- Use fast/snap sync; grab a snapshot for L2 where available.
- Open P2P and RPC ports. Enable TLS/HTTPS for all RPC endpoints.
- Set up Prometheus + Grafana monitoring. Alert on sync lag, disk pressure, and CPU spikes.
- Encrypt keystores; use HSM for validators. Schedule regular DB backups.
- For validators: generate keys, register stake, enable slashing protection DB.
RPC provider selection
- Confirm provider supports all chains you need (Ethereum, specific L2s).
- Store API keys in environment variables — never commit to repositories.
- Test
eth_blockNumber,eth_call, and WebSocket connectivity before going live. - Check current quotas on provider dashboards; estimate traffic to pick a plan or mix free tiers.
- Implement retry/backoff and automatic failover (on 429, switch provider).
- Use a provider fallback array:
provider.fallback([Chainstack, Alchemy, Infura]). - Log 429/500 errors to track rate limit headroom over time.
- Evaluate advanced needs: trace APIs, archive access, WebSockets, or dedicated nodes for production workloads.
Conclusion
Layer 1 vs Layer 2 infrastructure is not a choice between one or the other — it is a layered system where Ethereum provides security and settlement while Layer 2 networks provide execution, scalability, and user-facing performance. Understanding how these layers interact is critical when designing node infrastructure, RPC architecture, and multi-chain production systems.
The Ethereum stack has never been more capable. It’s also never been more operationally complex. You’re no longer choosing between one chain and another — you’re managing a layered system where each level has different security assumptions, different finality behavior, and different infrastructure requirements.
Getting that right means understanding not just how each layer works, but what it demands from your stack at 2am when something goes wrong.
Chainstack handles the infrastructure layer so you don’t have to: full and archive nodes, dedicated RPC endpoints, WebSocket support, and 70+ chains — including Ethereum, Arbitrum, Optimism, Polygon, StarkNet, and every other network covered in this guide. Request-based pricing means you’re not penalized for complex queries, and a 99.99%+ uptime SLA means your fallback list gets shorter.
Whether you’re spinning up your first L2 node or consolidating five providers into one, Chainstack gives you the foundation to build without the ops overhead.
Or talk to the team if you’re scoping infrastructure for a larger deployment.
FAQ
Finality speed and withdrawal behavior. Optimistic rollups (Arbitrum, Optimism) confirm fast on L2 but carry a 7-day Standard Bridge withdrawal delay. ZK-rollups finalize cryptographically once the proof hits L1 — withdrawals are faster. If your users move value L2→L1 frequently, ZK finality matters. Otherwise, optimistic rollups have a larger ecosystem and more tooling today.
Hosted is the right starting point for most teams. Self-hosted gives you full control and no rate limits, but adds real ops overhead — sync management, disk growth, client upgrades. The threshold to self-host is when hosted plan costs exceed what a cloud VM costs to run, or when you need custom configuration a provider won’t support. If you want the control of self-hosting without the full ops burden, Chainstack’s self-hosted option is a middle path worth evaluating.
Transactions stop confirming and APIs stop updating — even though Ethereum keeps running. Before it happens, know: Does your L2 support forced inclusion from L1? Can you still serve read requests from historical state? Are withdrawals safe during downtime? Most L2s have a forced inclusion path, but it’s not always obvious. Build the runbook before you need it.
Use one primary provider that covers all your chains, plus a fallback array for critical ones. Implement retry/backoff on 429s and auto-switch to a secondary endpoint. Store API keys in environment variables, never in code. A single provider with broad chain coverage cuts your operational surface significantly.
Ethereum DA posts transaction data directly to L1 — security matches Ethereum itself. Celestia uses light-node sampling to prove availability probabilistically, enabling higher throughput at lower cost but with weaker trust assumptions. Ethereum DA is the right default. Celestia makes sense when throughput pushes against what blobs can handle cost-effectively.
Free tiers are for development, not production. A mid-tier paid plan ($49–99/month) covers early single-chain production. Multi-chain with archive and WebSockets runs $150–300/month before you need dedicated nodes. Self-hosted cloud compute is roughly $500–700/month per node. Model your actual call volume against provider pricing — CU-weighted and request-based pricing behave very differently at scale.
Related reading