Ethereum
Ethereum Solana
Solana Hyperliquid
Hyperliquid Arbitrum
Arbitrum Base
Base BNB Smart Chain
BNB Smart Chain Tempo
Tempo Avalanche
Avalanche Aptos
Aptos TRON
TRON Ronin
Ronin zkSync Era
zkSync Era Optimism
Optimism Sonic
Sonic Polygon
Polygon Unichain
Unichain Fantom
Fantom Gnosis Chain
Gnosis Chain Sui
Sui Avalanche Subnets
Avalanche Subnets Polygon CDK
Polygon CDK Starknet Appchains
Starknet Appchains zkSync Hyperchains
zkSync Hyperchains












Building a Web3 AI trading agent from scratch

The fusion of decentralized finance and artificial intelligence is no longer a speculative trend. It is unfolding in real-time, and nowhere is this more evident than in the rise of local-first, AI-driven trading agents on Web3 infrastructure.
While much of the industry focuses on plugging pre-trained models into centralized services, a new generation of builders is embracing a more sovereign path that favors control, transparency, and full-stack understanding.
Let us walk through the design and implementation of a complete Web3 AI trading agent. Built from the ground up to run locally and train custom models, the system exemplifies a methodical progression from manual DeFi interaction to fully autonomous agent behavior.
An AI agent built the hard way
The trading agent project is not about deploying a single model or slapping GPT responses onto trading APIs. Instead, it aims to teach and operationalize a complete AI trading pipeline on the BASE blockchain using Uniswap V4. Each component is built with intentional friction: there are manual steps, infrastructure choices, and fine-tuning workflows that force a deep understanding of what a “Web3-native AI” system actually entails.
The project is local-first and stack-conscious. Wherever possible, operations run on the user’s machine, from Foundry-forked chains to Ollama-served LLMs. This decentralizes not just blockchain access but also AI model inference, a critical step toward privacy and resilience in Web3 intelligence systems.

Web3 infrastructure stack
The agent operates on BASE – an Ethereum Layer 2 that offers low fees and high throughput. This choice provides fertile ground for rapid trade execution without incurring the overhead of mainnet Ethereum.
Uniswap V4 is the AMM of choice, featuring a singleton architecture where all liquidity pools are governed by a single contract instance. This design dramatically reduces contract sprawl and improves composability.
Foundry serves as the core local blockchain toolkit. By forking the BASE mainnet, users can simulate and debug real-world trading scenarios without spending funds. It’s here that strategies can be tested and tuned before going live.
From general AI models to specialization
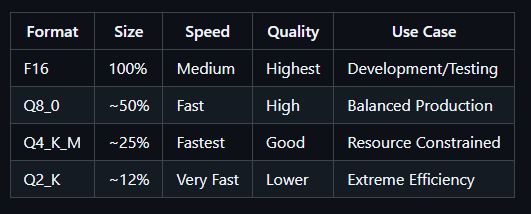
Model inference is handled locally through Ollama or Apple’s MLX-LM (for M-series chips). The stack is deliberately flexible, letting developers swap in different models, quantizations, and architectures as they see fit.
The core components are:
- Ollama: lightweight local inference
- MLX-LM: training and fine-tuning on Apple Silicon
- Gymnasium: reinforcement learning environments
- PyTorch: training GANs and custom nets
The architecture follows a teacher-student distillation process. A larger model like QwQ-32B generates optimized outputs, which are used to train a smaller, resource-efficient model (e.g., Qwen 2.5 3B) tailored to local inference and fast trading decisions.
From manual to agentic models
The development path mirrors the broader evolution of Web3 trading:
- Manual trading: MetaMask swaps via Uniswap
- Scripted bots: programmatic swaps on Uniswap V4 via Chainstack Trader Node
- Stateless agents: LLM-powered decisions without memory
- Dynamic agents: stateful logic, memory, and historical strategy tracking
Each layer adds complexity but also greater expressivity. Stateless agents offer quick insights based on live data, but stateful agents bring in learned behaviors, portfolio memory, and adaptive logic.
Synthetic data and model fine-tuning
Data scarcity in on-chain finance is a real challenge. To address this, the project uses GANs (Generative Adversarial Networks) to create synthetic ETH/USDC swap sequences modeled after Uniswap V4 behavior on BASE. These generated sequences are then validated and used for fine-tuning.
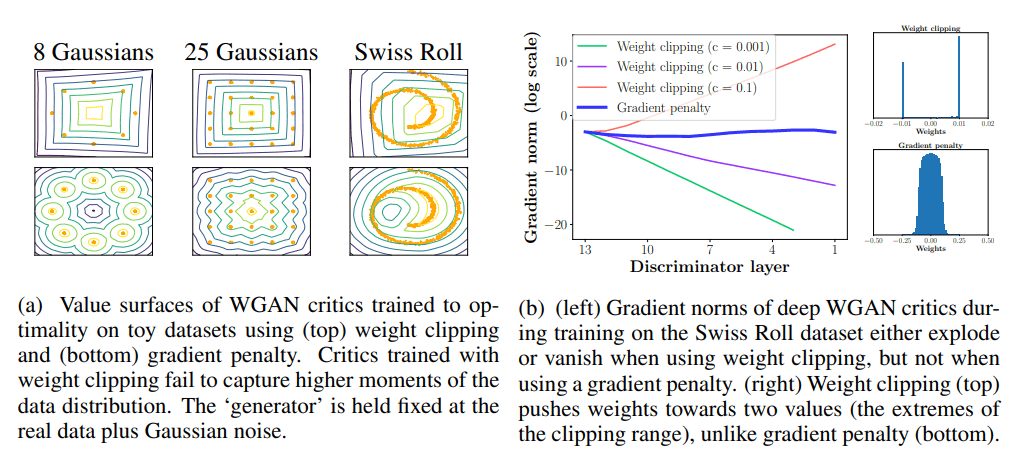
The training loop includes positional encoding, multi-head attention, and transformer-based GAN architectures, allowing the models to internalize the temporal logic of market actions. For stability, Wasserstein GAN with Gradient Penalty is used, with additional techniques like gradient penalty, minibatch discrimination, and diversity loss.
Knowledge compression via distillation
Once synthetic data is generated, the distillation process begins. The system uses OpenRouter to access large teacher models like QwQ-32B and guides the training of a smaller model. Key here is the “Chain of Draft” approach—short, structured reasoning steps that improve inference time and preserve logical flow.
The result is a lightweight, fine-tuned model that internalizes trading logic without relying on external APIs. Canary words such as “APE IN” (buy) and “APE OUT” (sell) verify that the trained model has truly absorbed task-specific knowledge rather than mimicking generic LLM behavior.
AI reinforcement learning and strategy
The final layer is a reinforcement learning module using Deep Q-Networks (DQN). The RL agent trains in a Gymnasium environment specifically designed to simulate Uniswap V4 market dynamics. Its reward structure balances profit optimization with risk and transaction costs.
What’s particularly noteworthy is the reuse of RL decisions to further fine-tune the LLM. By converting the RL agent’s trade decisions into conversational prompts, the model gains another layer of training—a technique that fuses symbolic learning with language-based reasoning.
Fusing the AI model and running the agent
The final LoRA adapter, containing all the learned weights, is fused into the base model and optionally converted into GGUF format for Ollama. This creates a self-contained, production-ready model that can be served locally for real-time inference.
Agents are launched through Python scripts that cycle through market evaluations, prompt the LLM, analyze rebalancing thresholds, and submit swap transactions on-chain. Whether operating in a dry-run fork or on BASE mainnet with Chainstack nodes, the agent retains full transparency.
You can find the full project repo here.
Building, not consuming
This project isn’t about outperforming hedge funds or launching the next HFT unicorn. It’s about understanding. By walking through each step of AI trading agent construction, developers learn the nuances of on-chain data, trading strategy formulation, LLM behavior, and data generation theory.
In a world increasingly flooded with opaque AI services and centralized automation, this project offers something radical: sovereignty over your stack. Whether you use it to learn, to experiment, or to deploy a custom system, the blueprint is now open.
Power-boost your project on Chainstack
- Discover how you can save thousands in infra costs every month with our unbeatable pricing on the most complete Web3 development platform.
- Input your workload and see how affordable Chainstack is compared to other RPC providers.
- Connect to Ethereum, Solana, BNB Smart Chain, Polygon, Arbitrum, Base, Optimism, Avalanche, TON, Ronin, Plasma, Hyperliquid, Scroll, Aptos, Fantom, Cronos, Gnosis Chain, Klaytn, Moonbeam, Celo, Aurora, Oasis Sapphire, Polygon zkEVM, and Bitcoin mainnet or testnets through an interface designed to help you get the job done.
- Fast access to blockchain archive data and gRPC streaming on Solana.
- To learn more about Chainstack, visit our Developer Portal or join our Telegram group.
- Are you in need of testnet tokens? Request some from our faucets. Sepolia faucet, Base Sepolia faucet, Hoodi faucet, BNB faucet, zkSync faucet, Scroll faucet, Hyperliquid faucet.
Have you already explored what you can achieve with Chainstack? Get started for free today.