Ethereum
Ethereum Hyperliquid
Hyperliquid Solana
Solana Arbitrum
Arbitrum BNB Smart Chain
BNB Smart Chain Base
Base Polygon
Polygon TRON
TRON Sui
Sui Robinhood
Robinhood



Solana deserialization AccountLoader & repr(C)

In the evolution of a Solana developer, there is a distinct turning point: the moment you move from building simple CRUD applications to architecting high-throughput, professional-grade protocols. When you reach this stage, you quickly realize that the “default” ways of handling data. While convenient, are often the primary bottlenecks holding back your program’s performance and scalability.
Most developers begin by relying on Borsh serialization. It’s the standard for the Anchor framework, providing a clean, Rust-idiomatic way to manage account state. However, as your state grows from simple counters to complex order books or massive gaming registries, Borsh reveals its physical limits. You start hitting the dreaded Stack offset exceeded errors, your Compute Unit (CU) consumption spikes into the hundreds of thousands, and you find yourself trapped by the runtime’s 10KB CPI limit and 4KB stack constraints.
To build serious protocols, you must change how your program “thinks” about memory. This is where Zero-Copy deserialization becomes mandatory. Instead of wasting precious cycles copying bytes from the account buffer into the program’s stack or heap, Zero-Copy allows you to map your data structures directly onto the raw account data. It’s the difference between moving a library’s worth of books every time you want to read one, and simply walking into the library and reading them where they sit.
In this deep dive, we are going to look under the hood of the Solana memory model. We’ll explore why Borsh fails at scale, how to implement AccountLoader with repr(C) layouts, and how to architect your programs to handle accounts up to 10MB without breaking the bank on Compute Units.
The runtime constraints: why borsh is a liability
In a standard execution environment, copying a few kilobytes of data is negligible. But the Solana High-Performance Runtime (Sealevel) isn’t a standard environment. It is a highly constrained eBPF-based VM where every byte moved and every instruction executed has a literal cost in Compute Units (CUs).
The stack problem
Solana programs have a notoriously small stack: 4KB.
When you use standard Borsh deserialization via Account<'info, T>, the program takes the raw account data and attempts to “reconstruct” it into a new instance of your struct on the stack. If your struct is large, say a 2KB state file and you have a few nested function calls, you will hit the Stack offset exceeded error almost immediately.
The heap problem
Even if you move the data to the heap, you aren’t safe. The heap is limited to 32KB. While this sounds like enough for simple logic, try deserializing an order book with 100 entries. Borsh will attempt to allocate memory for every single element, leading to massive CU consumption and eventual heap exhaustion.
The borsh tax
Every time you call instruction.accounts.account_name(), you are paying the “Borsh Tax.” This tax is composed of:
- CPU Cycles: Iterating through the byte buffer.
- Memory pressure: Creating duplicate copies of data that already exists in the input buffer.
- CU Waste: For a 10KB account, Borsh a lot of CUs just to make the data “readable” to your Rust code.
Zero-Copy effectively reduces this tax to nearly zero. By treating the account’s data buffer as the struct itself, we bypass the stack and heap limits entirely. We aren’t moving the library; we are just pointing to the shelf.
Memory layout & repr(C),the predictability of bytes
To achieve zero-copy, your program must be able to “overlay” a Rust struct directly onto a raw slice of bytes. However, Rust’s compiler (rustc) is flexible with how it organizes memory. By default, it uses repr(Rust), which allows the compiler to reorder fields to minimize padding or optimize for size.
While this is great for standard apps, it’s a disaster for blockchain state. If the compiler reorders fields differently between your program’s versions, or if the layout on-chain doesn’t match your local struct, you’ll read garbage data or crash.
The role of #[repr(C)]
The #[repr(C)] attribute tells the Rust compiler to use the C ABI (Application Binary Interface) layout. This ensures that the fields are laid out in memory in the exact order you define them in your code.
#[repr(C)]
pub struct MarketState {
pub version: u8, // Offset 0
pub bump: u8, // Offset 1
pub authority: [u8; 32], // Offset 2
}With repr(C), we can guarantee that if we look at the 2nd byte of the account data, it will always be the bump. This predictability is the foundation of zero-copy.
Enter bytemuck: Pod and Zeroable
To safely cast bytes to a struct, Anchor (under the hood) relies on the bytemuck crate. Two traits are critical here:
- Pod (Plain Old Data): This signals that the type is “simple”, it has no pointers, no
StringorVec, and every bit pattern is valid. This allows us to safely interpret a slice of bytes as this type. - Zeroable: This ensures that the type can safely be initialized as all zeros. This is vital when you create a new account and need to ensure the memory is clean.
Why No Vec or String?
In Zero-Copy, we are mapping a fixed-size window onto a fixed-size account buffer. A Vec in Rust is actually a pointer to a location on the heap, a length, and a capacity. If you tried to use zero-copy with a Vec, you’d just be reading a “dead” pointer that points to some memory address on the machine that originally created the account—not the actual data.
Rule of Thumb: If the size isn’t known at compile-time, it cannot be in a zero_copy struct. You must use fixed-size arrays: [u8; 32] instead of Pubkey (if not using the Anchor wrapper), or [Order; 1000] instead of Vec<Order>.
Example:
use anchor_lang::prelude::*;
use bytemuck::{Pod, Zeroable};
use std::mem::{size_of, align_of};
#[repr(C)]
#[derive(Default, Debug, Clone, Copy, Pod, Zeroable)]
pub struct MarketState {
pub version: u8,
pub _padding1: [u8; 7],
pub volume: u64,
pub is_active: u8, // Use u8 instead of bool: 0 = false, 1 = true
pub _padding2: [u8; 7],
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_memory_layout() {
let state = MarketState {
version: 1,
volume: 100,
is_active: 1,
..Default::default()
};
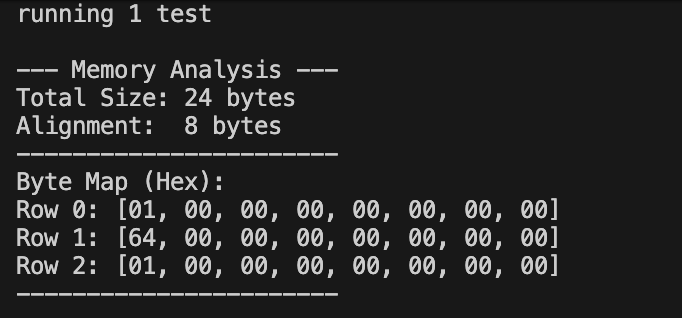
println!("\n--- Memory Analysis ---");
println!("Total Size: {} bytes", size_of::<MarketState>());
println!("Alignment: {} bytes", align_of::<MarketState>());
println!("-----------------------");
let bytes = bytemuck::bytes_of(&state);
println!("Byte Map (Hex):");
for (i, chunk) in bytes.chunks(8).enumerate() {
println!("Row {}: {:02X?}", i, chunk);
}
println!("-----------------------\n");
}
}Output:
The safety guards: Pod and Zeroable
By deriving Pod and Zeroable, we are making a contractual promise to the compiler:
Zeroable: “It is safe to fill this account with zeros.” This is crucial because when a new account is created on Solana, it starts as a blank slate of zeros.Pod(Plain Old Data): “This struct is just a bag of bytes.” No pointers, no strings, no hidden metadata. This allowsbytemuckto safely “cast” the raw account buffer directly into this struct.
The alignment strategy (repr(C))
Without #[repr(C)], the Rust compiler might decide to put is_active right after version to save space. While that sounds efficient, it would break 64-bit alignment for the volume field. By using repr(C), we force the fields to stay in the exact order we wrote them, matching the C standard used by the Solana eBPF VM.
This is the part that often confuses developers. Why do we need _padding1 and _padding2?
Manual padding: solving the hidden gap
_padding1: Becausevolumeis au64, the CPU requires it to start at an 8-byte boundary. Sinceversiononly takes 1 byte, there is a 7-byte “hole” before the next 8-byte boundary. By defining_padding1, we turn that hole into a real field, satisfying theNoUninitrequirement._padding2: A struct’s total size must be a multiple of its alignment (in this case, 8). Our data totals 17 bytes (1+7+8+1). To reach the next multiple of 8 (24 bytes), we add 7 more bytes of padding at the end.
Note: In
repr(C), the alignment of the entire struct is determined by the largest alignment requirement of any of its individual fields, u64 = 8bytes.
Why use u8 instead of bool?
You’ll notice we used pub is_active: u8. In Rust, a bool is strictly 1 byte, but it cannot be just any value, it must be 0 or 1. If the account data somehow had a 2 in that spot, the program would crash. Since Pod requires that any bit pattern be valid, we use u8 and treat 0 as false and 1 (or any non-zero) as true.
The AccountLoader pattern, direct buffer access
In a standard Anchor program, when you use Account<'info, MyData>, the framework performs the deserialization before your instruction logic even starts. With Zero-Copy, we shift that responsibility to the developer. We use AccountLoader, which acts as a lazy, safe wrapper around the account’s data.
The Mechanics of load() and load_mut()
When you use AccountLoader, the data isn’t mapped until you explicitly ask for it. This is handled through two primary methods:
load(): Returns aRef<T>. This is for read-only access. Because it uses Rust’s internalRefCellmechanics, you can have multiple immutable loads of the same account in the same scope.load_mut(): Returns aRefMut<T>. This is for write access. Crucially, if you try to callload_mut()twice on the same account in the same instruction, your program will panic. This is Solana’s way of enforcing Rust’s “one mutable reference” rule at runtime.
Example
Notice how we no longer access fields via ctx.accounts.market.field. Instead, we “load” the account into a local variable that acts as a pointer.
pub fn process_trade(ctx: Context<Trade>, amount: u64) -> Result<()> {
// map the account data to the 'market' variable
let mut market = ctx.accounts.market.load_mut()?;
// market now behaves like a standard Rust struct
market.total_volume += amount;
// No need to call 'exit' or 'save'—the changes are
// written directly to the account buffer in real-time.
Ok(())
}Why Ref<T> and RefMut<T>?
Why load() doesn’t just return &T? Under the hood, the account data is owned by the Solana runtime. Anchor uses these “smart pointers” to ensure that:
- The memory stays locked while you’re using it.
- You don’t accidentally create data races.
- The account is correctly marked as “dirty” so the runtime knows to persist the changes back to the ledger when the transaction finishes.
The “borrow” pitfall
A common senior-level mistake is trying to pass a Ref or RefMut into a helper function while still holding a reference in the main instruction.
// AVOID THIS
let market = ctx.accounts.market.load_mut()?;
calculate_fees(market); // Passing ownership of the RefMut
market.volume += 10; // ERROR: market was movedInstead, you should pass a reference to the data inside the loader, or scope your loads carefully. This keeps your Compute Unit usage low because you aren’t re-loading or re-mapping the buffer multiple times.
Scaling beyond 10KB, the two-step initialization
One of the most frustrating moments for a Solana developer is hitting the 10KB “Wall.” You’ve designed your zero-copy struct, you’ve set the space to 50KB, and you call anchor test, only to see your transaction fail with a cryptic CPI error.
The 10KB CPI constraint
The issue isn’t Zero-Copy, it’s the init constraint. When you use #[account(init, ...)], Anchor performs a Cross-Program Invocation (CPI) to the System Program to create the account. The Solana runtime restricts the amount of data that can be allocated via CPI to 10,240 bytes.
If you want to build a 1MB order book or a 5MB game state, the init constraint is physically incapable of creating it. To scale to the 10MB architectural limit, you must use the Two-Step Initialization pattern.
The pattern: external creation + zero constraint
Instead of letting the program create the account, you (the client) create it before you call the program.
- Step 1 (Client-side): Use the System Program to create a “naked” account with the full 1MB of space and transfer its ownership to your program.
- Step 2 (On-chain): Use the
zeroconstraint in Anchor. This tells Anchor: “This account already exists, it is owned by this program, and it is currently filled with zeros. Do not try to create it, just verify it’s empty and let me initialize it.”
On-chain implementation
In your instruction context, swap init for zero. Note that zero implies mut because you are about to write the discriminator.
use anchor_lang::prelude::*;
use bytemuck::{Pod, Zeroable};
declare_id!("Bo8J1of9EuuGw3DvSgTdV7Fug65oD7cERLsf5rzF6PG4");
#[program]
pub mod zero_copy_deep_dive {
use super::*;
// Initialize the account on-chain
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
// load_init() sets the 8-byte Anchor discriminator and maps the buffer
let mut market = ctx.accounts.market.load_init()?;
market.version = 1;
market.total_volume = 0;
market.is_active = 1;
msg!("Market initialized!");
Ok(())
}
// Update the data using Zero-Copy
pub fn update_volume(ctx: Context<UpdateMarket>, amount: u64) -> Result<()> {
// load_mut() maps the existing account buffer for writing
let mut market = ctx.accounts.market.load_mut()?;
market.total_volume = market.total_volume.checked_add(amount).unwrap();
msg!("Volume updated directly in memory to: {}", market.total_volume);
Ok(())
}
}
#[account(zero_copy)]
#[derive(Default, Debug)]
pub struct MarketState {
pub version: u8, // 1 byte
pub _padding1: [u8; 7], // 7 bytes padding for 8-byte alignment
pub total_volume: u64, // 8 bytes
pub is_active: u8, // 1 byte (using u8 instead of bool for Pod safety)
pub _padding2: [u8; 7], // 7 bytes padding to make total size multiple of 8 (24 bytes)
}
#[derive(Accounts)]
pub struct Initialize<'info> {
#[account(
init,
payer = authority,
space = 8 + std::mem::size_of::<MarketState>() // 8 (disc) + 24 (data) = 32 bytes
)]
pub market: AccountLoader<'info, MarketState>,
#[account(mut)]
pub authority: Signer<'info>,
pub system_program: Program<'info, System>,
}
#[derive(Accounts)]
pub struct UpdateMarket<'info> {
#[account(mut)]
pub market: AccountLoader<'info, MarketState>,
pub authority: Signer<'info>,
}Client-side implementation (TypeScript)
You must bundle the account creation and the program call into the same transaction (or sequential ones) to ensure security.
import * as anchor from "@coral-xyz/anchor";
import { Program } from "@coral-xyz/anchor";
import { ZeroCopyDeepDive } from "../target/types/zero_copy_deep_dive";
import { expect } from "chai";
describe("zero_copy_deep_dive", () => {
const provider = anchor.AnchorProvider.env();
anchor.setProvider(provider);
const program = anchor.workspace.ZeroCopyDeepDive as Program<ZeroCopyDeepDive>;
it("Initializes and Updates the volume!", async () => {
const marketKeypair = anchor.web3.Keypair.generate();
console.log("Available methods:", Object.keys(program.methods));
// Initialize the account
// This creates the account and changes owner from SystemProgram to our Program
await program.methods
.initialize()
.accounts({
market: marketKeypair.publicKey,
authority: provider.wallet.publicKey,
})
.signers([marketKeypair])
.rpc();
console.log("Account initialized.");
// Update the volume
// This will now pass because the account is owned by the program
const updateAmount = new anchor.BN(500);
await program.methods
.updateVolume(updateAmount)
.accounts({
market: marketKeypair.publicKey,
authority: provider.wallet.publicKey,
})
.rpc();
// Verify
const account = await program.account.marketState.fetch(marketKeypair.publicKey);
console.log("On-chain Volume:", account.totalVolume.toString());
expect(account.totalVolume.toNumber()).to.equal(500);
expect(account.isActive).to.equal(1);
});
});Output

By shifting the allocation to the client-side, you bypass the CPI limit entirely. This architecture allows your program to manage vast amounts of data up to 10MB, while maintaining the same low Compute Unit costs we discussed in previously. You are essentially using the blockchain as a high-speed, direct-mapped disk.
Summary
Zero-Copy architecture transforms Solana state management from a copy-heavy process into a direct memory-mapping operation. By eliminating the Borsh serialization tax, you achieve $O(1)$ efficiency and massive CU savings, though this requires taking direct responsibility for your data’s physical layout.
Ensuring strict 8-byte alignment through manual padding and swapping bool for u8 flags are essential steps to satisfy the hardware and safety constraints of the SBF VM. Ultimately, by mastering the ownership handshake and leveraging AccountLoader, you can architect professional-grade protocols that scale to 10MB without hitting runtime bottlenecks. Architect for the buffer, not the copy.
Reliable Solana RPC infrastructure
Getting started with Solana on Chainstack is fast and straightforward. Developers can deploy a reliable Solana node within seconds through an intuitive Console — no complex setup or hardware management required.
Chainstack provides low-latency Solana RPC access and real-time gRPC data streaming via Yellowstone Geyser Plugin, ensuring seamless connectivity for building, testing, and scaling DeFi, analytics, and trading applications. With Solana low-latency endpoints powered by global infrastructure, you can achieve lightning-fast response times and consistent performance across regions.
Start for free, connect your app to a reliable Solana RPC endpoint, and experience how easy it is to build and scale on Solana with Chainstack – one of the best RPC providers.
FAQ
Instead of copying account data into a new struct on the stack or heap, zero-copy maps your struct directly onto the raw account buffer. You read the data where it already lives. The compute cost becomes constant regardless of account size — critical once your state grows past a few kilobytes.
AccountLoader instead of Account? When your struct exceeds ~1–2 KB, or when you need accounts larger than 10 KB (which require the two-step init pattern). For simple counters or small config accounts, Account is fine — the ergonomics outweigh the CU savings at that scale.
#[repr(C)] on zero-copy structs? Without it, the Rust compiler can reorder your fields for optimization. On-chain, that means a program upgrade could silently change the byte layout, causing reads to return garbage. repr(C) locks field order to exactly what you wrote, matching the C ABI that the Solana eBPF VM expects.
Vec or String in zero-copy structs? A Vec is a heap pointer plus length and capacity — not actual data. When stored in an account buffer and read back later, that pointer points nowhere. Use fixed-size arrays instead: [Order; 1000] not Vec<Order>, [u8; 64] not String.
load(), load_mut(), and load_init()? load() is read-only, callable multiple times in the same scope. load_mut() is write access — calling it twice on the same account panics. load_init() is for new accounts only: it skips the discriminator check, writes it, then returns a mutable reference.
The init constraint uses CPI under the hood, capping allocation at 10,240 bytes. Split it into two steps: your client calls the System Program directly to create and fund the account, transferring ownership to your program. Then your on-chain instruction uses the zero constraint instead of init — it skips CPI, verifies the account is blank, and writes the discriminator. Maximum account size is 10 MB.
Learn more about Solana architecture from our articles
- Solana Token-2022 Metadata
- Where Token Metadata Lives on Solana
- SPL Token Program Architecture
- Architecture & Parallel Transactions
- Solana Interest-Bearing Tokens: Inside the Mint Extension
- Account Model and Transactions
- Anchor Accounts: Seeds, Bumps, PDAs
- Instructions and Messages
- Transaction, Serialization, Signatures, Fees, and Runtime Execution