Ethereum
Ethereum Hyperliquid
Hyperliquid Solana
Solana Arbitrum
Arbitrum BNB Smart Chain
BNB Smart Chain Base
Base Polygon
Polygon TRON
TRON Sui
Sui Tempo
Tempo Monad
Monad Avalanche
Avalanche Aptos
Aptos Ronin
Ronin zkSync Era
zkSync Era Optimism
Optimism Sonic
Sonic Unichain
Unichain Fantom
Fantom Gnosis Chain
Gnosis Chain







Ethereum nonce management: preventing stuck transactions

TL;DR
In production, one stuck transaction doesn’t just fail — it freezes every transaction that was supposed to come after it from the same account. Ethereum nonce management is what keeps that from happening at scale. This happens because transactions from one account have to be processed in strict order, so a single blocker holds up everything queued behind it. Keeping the line moving sounds simple, but doing it safely at scale is not: you have to track order yourself, coordinate senders that would otherwise step on each other, tell the difference between stuck and merely slow, and clear the blocker without making things worse. This article walks through those pieces and the traps that show up between them.
Intro
In EVM: Practical explanation of how gas fee works we saw why a single transaction gets stuck: if the priority fee you offered validators is too low, the transaction sits in the mempool and eventually times out. That’s annoying when it happens once. In production, it’s a lot worse.
That’s why robust ethereum nonce management starts before you ever send a transaction. Imagine a backend that signs and broadcasts transactions all day — a market maker, a bridge filler, an oracle updater, a payout service. Now imagine one of those transactions gets stuck. The next one you send from the same account won’t land either. Neither will the one after that. The symptoms pile up fast: receipts that never arrive, retry loops that keep signing new transactions on top of the blocked one, queues that grow without bound, and on-chain state that drifts from what your service thinks it has done. Your entire pipeline has frozen while still looking busy.
This article walks through how ordering actually works, why the naive approach breaks at scale, how to build a local tracker that stays consistent under load, and how to detect and replace stuck transactions without making things worse. We’ll also cover two shifts worth knowing about — private mempools and L2 sequencers — that change what “stuck” even means.
What is a nonce, and why does one stuck tx block all the others?
Every transaction from an Ethereum account carries a nonce — a counter that starts at zero and goes up by one every time that account sends a transaction. The network enforces a strict rule: a transaction with nonce N cannot be included at an earlier position than the transaction with nonce N-1. No gaps, no reordering.
This is what makes the stuck-transaction problem so bad at scale. If your service has sent nonces 42, 43, 44, 45, and 46, and nonce 42 is stuck because it was underpriced, then 43 through 46 are also stuck. They’re not “slow” — they’re literally unminable. Block builders will look at them, see the missing 42, and ignore all of them.

This is called a nonce hole. The fix is not to bump nonce 46; it’s to fulfill nonce 42. If you remember only one thing from this article, make it that: always fix the oldest stuck transaction first.
Why asking the node for the next nonce doesn’t scale
The obvious way to get the next nonce is to ask the node: eth_getTransactionCount(address, "pending"). This returns the account’s nonce including everything already in that node’s mempool. Done, right?
Two problems.
First, the “pending” view is a per-node thing. Different nodes can disagree on what’s in the mempool. Some transactions haven’t propagated yet, some have expired, some came in through private routes that bypass the public mempool entirely. If you send a transaction through a private relay and then query a different RPC for the pending nonce, the private transaction won’t be counted. The next nonce you use will collide. Getting consistent reads from a reliable provider like Chainstack reduces this drift, but no single node ever sees everything.
Second, and worse, is the concurrency trap. When two workers ask for the pending nonce at the same time, they both get the same number. They both sign a transaction with it. One gets accepted; the other either fails with a replacement transaction underpriced error, or silently overwrites the first one.

Here’s the anti-pattern in code, which you should not copy into production:
// BAD — race-prone
const nonce = await provider.getTransactionCount(wallet.address, "pending");
await wallet.sendTransaction({ ...tx, nonce })Under single-worker load this works. The first time you send two transactions concurrently, it stops working.
Local nonce management: the foundation
The fix is to maintain one source of truth for each signing account — an in-process counter, serialized access, and a single path for reconciling with chain state. Here’s a minimal tracker in ethers v6:
class NonceTracker {
constructor(provider, address) {
this.provider = provider;
this.address = address;
this.next = null;
this.lock = Promise.resolve();
}
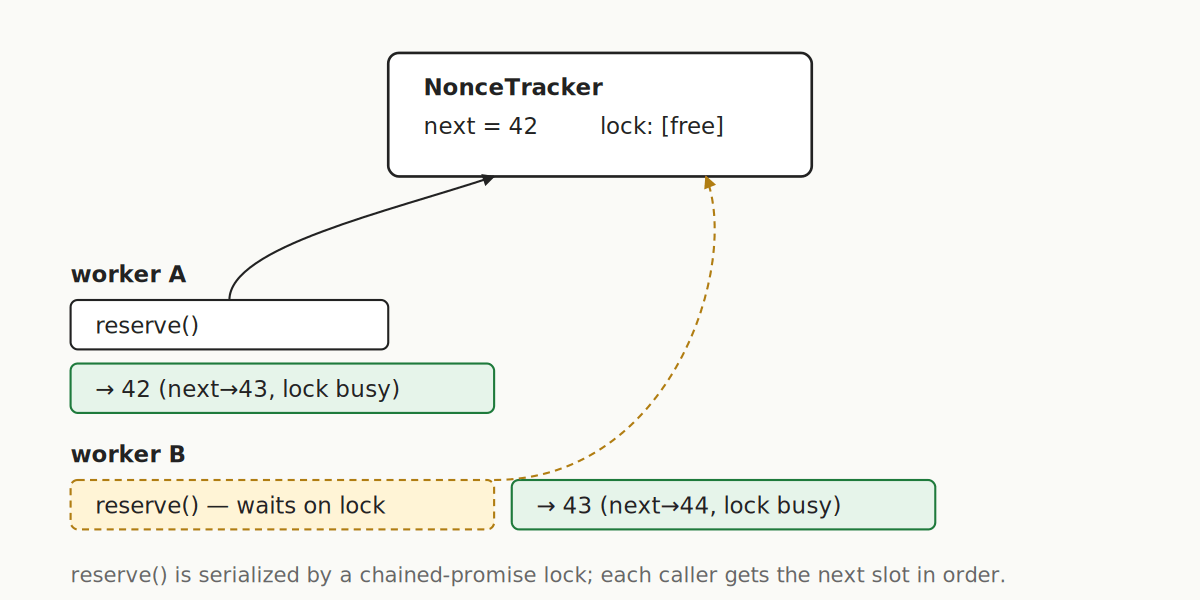
async reserve() {
const prev = this.lock;
let releaseNext;
this.lock = new Promise(r => (releaseNext = r));
await prev;
if (this.next === null) {
this.next = await this.provider.getTransactionCount(this.address, "pending");
}
const n = this.next++;
releaseNext();
return n;
}
reset(n) { this.next = n; }
}The chained-promise pattern serializes reserve() calls so concurrent callers line up instead of racing. The first call bootstraps from the chain; every subsequent call just increments. If a send fails, the caller must call reset(failedNonce) so the next send reuses that slot instead of leaving a gap.
A few rules for making this production-safe:
- Persist next somewhere durable. A crash mid-send will desync the counter from the chain.
- On boot, take the max of the persisted value and
getTransactionCount(..., "pending"). - Do not share a signing key across processes without an external lock. If you must, a single dedicated signer service is simpler and safer than scattering Redis locks around.
- Respect the per-account mempool cap. Ethereum nodes cap how many transactions one account can have sitting in the pool — roughly 16 in the pending sub-pool and ~64 more in the queued sub-pool as typical defaults. Overflow doesn’t vanish instantly; it either waits in the queued area for a missing nonce or gets evicted under global price pressure when the whole pool is full. The practical takeaway is to avoid holding a large backlog of pending transactions per account — the more you keep in flight, the closer you get to these limits and the higher the chance of losing transactions you thought were safely queued. Confirm what you send before piling on more.
Detecting and replacing a stuck transaction
Sending is half the job. The other half is noticing when something didn’t land and doing something about it.
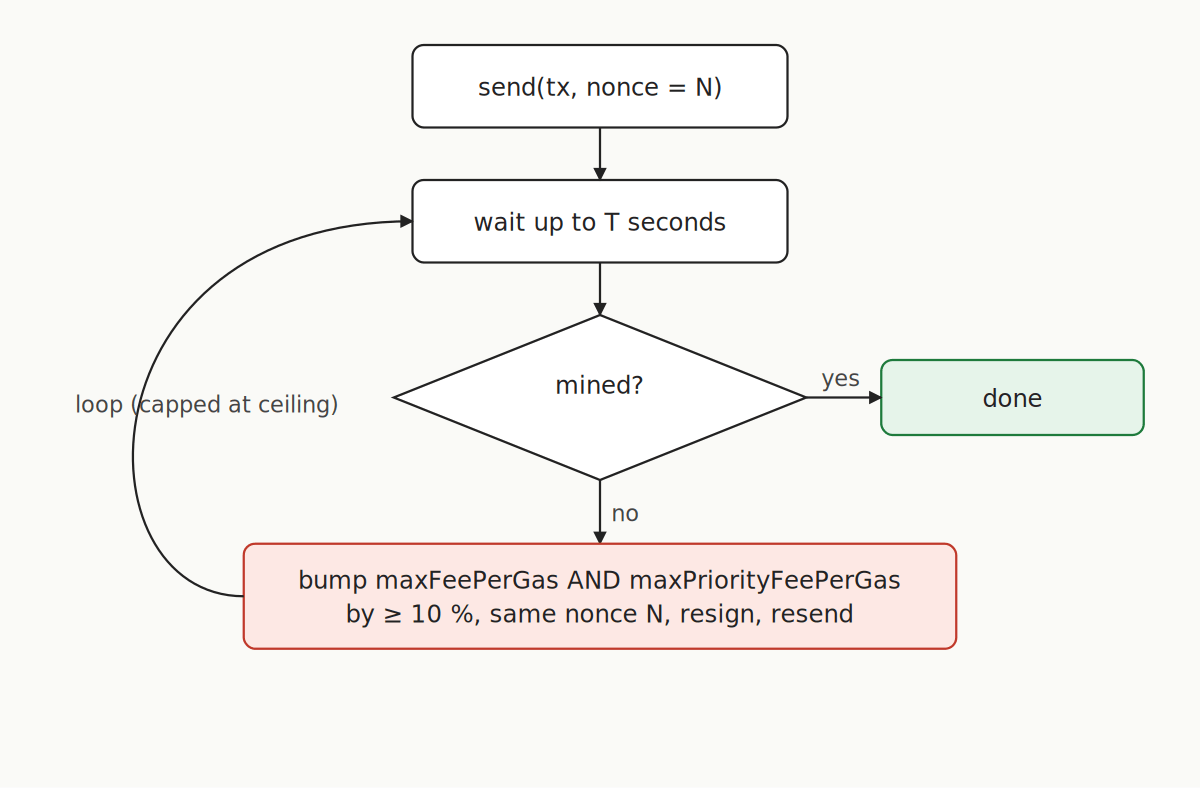
The detection pattern is a polling loop with a timeout — tx.wait(1, timeoutMs) in ethers, or equivalent receipt polling. If a transaction hasn’t mined within, say, 30–60 seconds on L1 (much less on an L2), treat it as stuck and replace it.
Replacement has strict rules. The new transaction must have the same nonce and both maxFeePerGas and maxPriorityFeePerGas at least 10% higher than the original. Raising only one of the two is not enough — the node will reject the replacement with replacement transaction underpriced before it even enters the mempool, and the original stays stuck. Both values have to clear the 10% bar, otherwise the attempt is simply discarded and you’re back where you started with the same blocker in place.
A speed-up in ethers:
const bumped = {
to: original.to, value: original.value, data: original.data, nonce: original.nonce,
maxFeePerGas: (original.maxFeePerGas * 12n) / 10n,
maxPriorityFeePerGas: (original.maxPriorityFeePerGas * 12n) / 10n,
};
await wallet.sendTransaction(bumped);A cancel is the same pattern with the payload cleared — a zero-value self-send at bumped fees:
await wallet.sendTransaction({
to: wallet.address, value: 0n, data: "0x", nonce: original.nonce,
maxFeePerGas: (original.maxFeePerGas * 12n) / 10n,
maxPriorityFeePerGas: (original.maxPriorityFeePerGas * 12n) / 10n,
});Escalate in steps (1.2×, 1.5×, 2×) with a hard ceiling; above that, alert rather than keep burning. The receipt of either the original or the replacement settles the nonce — whichever lands first, your tracker’s next slot is free.
Skipping the public mempool: private routes
As we mentioned previously, many production services don’t use the public mempool at all. That’s worth unpacking, because it changes how you manage nonces too.
Private relays — Flashbots Protect, MEV-Share, direct builder endpoints — accept your signed transaction and forward it straight to block builders. Nothing shows up in the public mempool, so front-running and sandwich bots can’t see it. For any value-sensitive send (DEX trade, liquidation, arb), skipping the public mempool is the default choice today — sending through it leaks your intent to bots that will reorder or copy your trade before it lands.
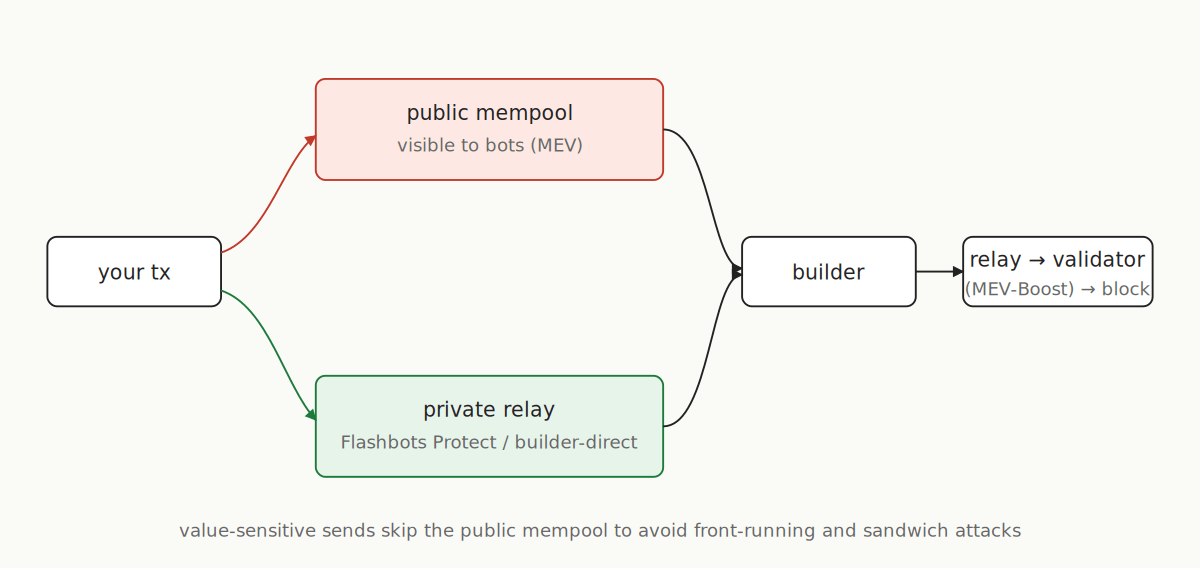
What actually gets that private transaction onto the chain is MEV-Boost. Post-Merge, validators don’t build their own blocks anymore — most of them run MEV-Boost as a sidecar that accepts a fully-formed block from an outside builder (via a relay) and signs whichever one pays the most. Builders are the ones reading private-relay flow, Flashbots bundles, and the public mempool, packing them into a block, and competing on tip. The relay’s job is to hand the builder’s block to the validator without either side seeing the other’s full payload until the validator has committed to it.
The nonce-management consequence is the one we already flagged: a private transaction only lands if some MEV-Boost-connected builder picks it up and wins the auction for a slot. If your bundle isn’t profitable, if the relay filters it, or if the winning builder for that slot ignored your route, the transaction just sits there — no mempool entry, no revert, no signal. Your detection-and-replace loop is the only thing that will notice.
There’s a subtle nonce issue worth knowing. If you submit a transaction through Flashbots Protect and then ask the Flashbots RPC for your pending nonce, it will not include that private transaction — unless you EIP-191-sign the JSON-RPC payload and include it in an X-Flashbots-Signature header. Without that signed request, the RPC returns a nonce that ignores your in-flight private transaction, so the next one you sign reuses the same slot and collides. This is exactly the kind of cross-system inconsistency a local tracker sidesteps: if your own counter is the source of truth, you never have to ask.
Private routes don’t remove the need for nonce discipline. A private transaction occupies the same nonce slot as a public one, and it can still get stuck — if no builder picks it up, it just sits there, invisibly. Detection and replacement are still your problem. Chainstack’s protected transaction endpoints plug into this same flow and let you keep your existing monitoring in place.
L2 nonces: sequencer-based chains
Rollups like Arbitrum, Base, and Optimism run a centralized sequencer that orders transactions. Per-account nonces still apply, and the cascade rule is identical — one stuck tx blocks all subsequent ones from the same account. The differences are in the failure modes.
Inclusion on a healthy L2 is sub-second, so “stuck” is rare when fees are set correctly. The sequencer is the new single point of failure: if it’s down or censoring, nothing mines for anyone. Treat sequencer uptime as a first-class health signal; Chainlink publishes L2 sequencer uptime feeds specifically for this.
The escape hatch is force inclusion. Both Arbitrum and the OP stack let you submit a transaction directly to the L1 inbox; the sequencer is then required to include it. Optimism and Base honor these near-immediately; Arbitrum enforces a sequencer-delay window of around 24 hours before the force is granted. Slow, but censorship-resistant.
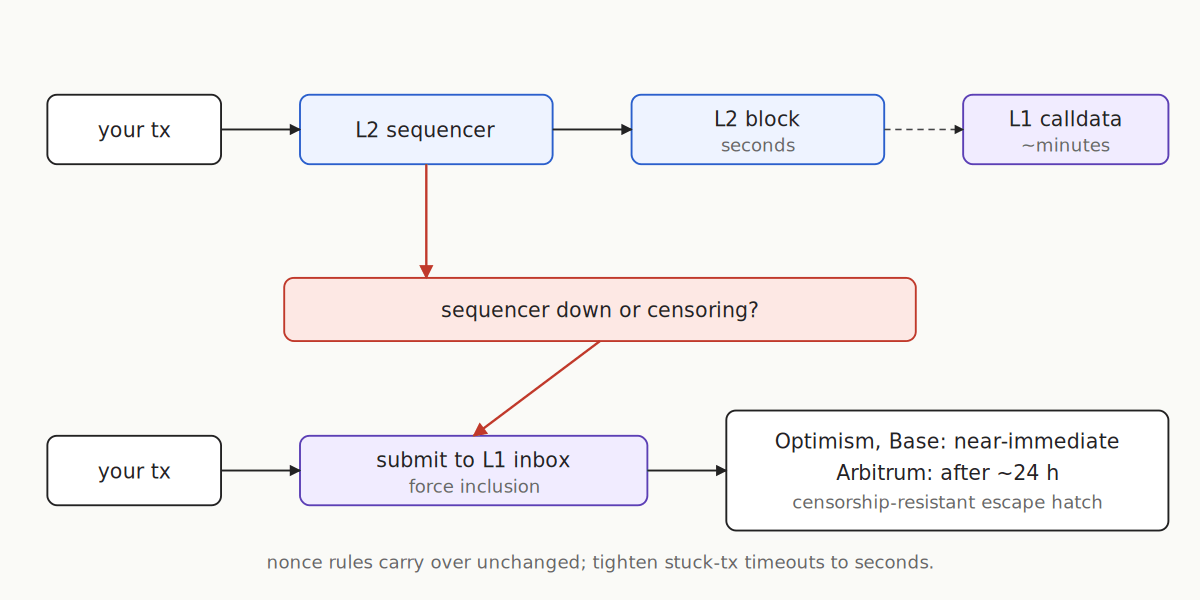
Your nonce tracker and replacement logic carry over unchanged. Tighten the stuck-tx timeout to seconds and wire sequencer health into your alerts.
Conclusion
A quick checklist to take into production:
- One nonce source of truth per account. Never call
getTransactionCounton the hot path. - Serialize sends per account with an in-process lock; consolidate to one signer service across processes.
- Monitor receipts with a timeout, and always fix the oldest stuck transaction first.
- Respect the per-account mempool cap; throttle or shard signing keys before you hit it.
- Use private routes for MEV-exposed sends; watch L2 sequencer health.
Build vs buy: ethers’ built-in NonceManager gives you local sequencing but no re-broadcast or fee escalation, so you’re still on the hook for detection and replacement. A managed relayer like OpenZeppelin Defender ships the full loop — atomic nonce assignment, gas re-estimation, automatic resubmission — and is often cheaper than rolling your own. Either way, all of it rests on the RPC underneath; consistent pending reads, stable websocket streams, and private transaction endpoints from a reliable provider like Chainstack are what stop nonce drift from compounding in the first place.
Getting started on Chainstack
The NonceTracker above assumes what’s underneath it is reliable — consistent pending reads, stable WebSocket streams for receipt polling, and private transaction support when you need to skip the mempool. That’s what Chainstack’s global RPC infrastructure is built for. Chainstack supports Ethereum mainnet, all major L2s (Arbitrum, Base, Optimism), and private transaction endpoints — so your nonce management strategy and your RPC layer can scale together.
FAQ
A nonce is a per-account counter that increments by one with every transaction an address sends. Ethereum requires transactions from the same account to be included in strict nonce order with no gaps, which is why a single underpriced or dropped transaction can freeze every later transaction from that account until it is mined or replaced.
Resend with the same nonce and both maxFeePerGas and maxPriorityFeePerGas raised by at least 10%. To cancel, use the same nonce with a zero-value self-send and empty data at the bumped fees. Raising only one of the two fee fields gets rejected with replacement transaction underpriced, and the original stays stuck.
Yes. A private transaction occupies the same nonce slot as a public one and can still get stuck if no builder picks it up. The Flashbots RPC will not return your in-flight private nonce unless the request is EIP-191-signed with an X-Flashbots-Signature header — a strong argument for treating a local tracker, not the RPC, as the source of truth
Both workers will read the same pending nonce and sign transactions with the same slot. One will be accepted; the other will either fail with replacement transaction underpriced or silently overwrite the first, depending on fee levels. The fix is serialized access — a single in-process lock or a dedicated signer service per account.
As of current Geth/Reth defaults, roughly 16 transactions in the pending sub-pool and ~64 more in the queued sub-pool per account. Exceeding these limits means transactions are either held in the queued area (waiting on a nonce gap to close) or evicted entirely under global mempool pressure. Verify the exact figures against the Geth or Reth release notes for your node version before deploying.
Yes — per-account nonces and the cascade-blocking rule are identical on Arbitrum, Base, and Optimism. The main differences are timeout sensitivity (stuck is “seconds” not “minutes”) and the failure mode: instead of mempool congestion, you’re watching for sequencer downtime or censorship. Use Chainlink’s L2 sequencer uptime feeds as a health signal, and know your force-inclusion escape hatch for each chain.
Additional resources
Ethereum core references
- EIP-1559: Fee market change — official specification
- Ethereum JSON-RPC API —
eth_getTransactionCount - Geth mempool transaction pool documentation
Related Chainstack articles