




Introduction: a different kind of L2
Most Ethereum Layer 2s are built around a single premise: make transactions cheaper. MegaETH starts from a different assumption entirely. It is an Ethereum-compatible L2 that targets 100,000 transactions per second with blocks produced every 10 milliseconds, not to reduce costs but to eliminate latency. At that cadence, the category of applications worth building changes. Real-time trading, on-chain gaming, and high-frequency state updates stop being theoretical and start being tractable.
It also changes what becomes hard to build. On a slower chain, a mediocre RPC provider or a naive polling loop is an inconvenience. On MegaETH, those same choices become immediate failure modes. When a new block arrives every 10 milliseconds, infrastructure that was never designed for that cadence breaks in ways that are difficult to anticipate and easy to misdiagnose.
This is why building on MegaETH feels less like conventional blockchain development and more like low-latency systems engineering. The RPC provider you choose, the subscription method you use, the transport layer you default to all carry consequences that simply do not appear on slower chains.
MegaETH architecture: how it actually works
MegaETH is built on the OP Stack and settles to Ethereum L1, which means it inherits Ethereum’s security model and its familiar JSON-RPC interface. But the execution layer above that foundation works differently from any other OP Stack chain.

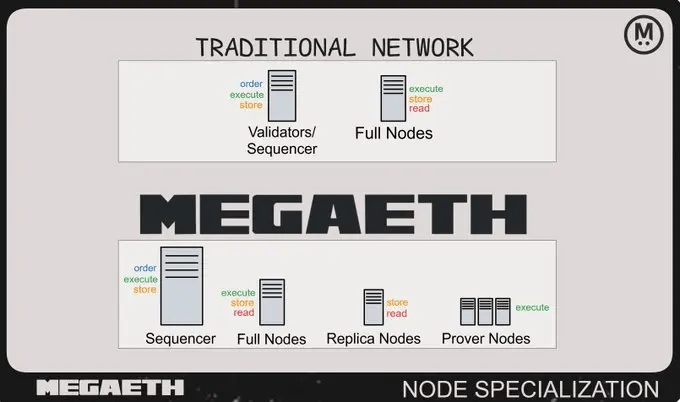
Standard EVM block headers were not designed for 100 blocks per second. Mini-blocks solve this by stripping the format down to what real-time streaming actually needs. Transactions, receipts, and state changes, produced every 10 milliseconds. EVM blocks follow every second, in the standard Ethereum format that existing wallets, indexers, and tooling already understand. Every transaction appears in both. The mini-block gets you the result fast. The EVM block packages it into something the rest of the ecosystem can read.
For most developers, EVM blocks are invisible in the sense that existing tooling works without modification. Where the distinction becomes a design decision is in event-driven architecture. If your application subscribes to new block headers and reacts to on-chain state, what it actually receives depends on what the RPC layer exposes. A provider that only surfaces EVM blocks gives you one event per second regardless of how fast the chain moves. A provider that exposes mini-block subscriptions gives you one event every 10 milliseconds. For a trading system or game backend, those are not equivalent choices.
The other assumption MegaETH breaks is around gas estimation. The chain uses a multidimensional gas model that tracks multiple resource dimensions rather than collapsing everything into a single gas number. Local EVM simulation, the approach most Ethereum tooling defaults to, does not correctly model this. Developers who rely on Hardhat or Foundry for gas estimates and carry those numbers into production will encounter failures that do not appear in testing. Gas estimation on MegaETH needs to go through the RPC, not local simulation. It is a small change in practice but one that catches teams off guard consistently enough to be worth treating as a first principle.
Throughput at 100K TPS: what it means in practice
The 100,000 TPS figure is real, but it is not the number that should drive your infrastructure decisions. The number that matters is how many RPC requests your application generates as a consequence of that throughput.
At 10ms block cadence, an application polling for new blocks needs to fire at least 100 requests per second just to stay current. One that subscribes to events and processes logs on each block handles 100 subscription notifications per second at steady state. One that tracks transaction confirmations is doing so against a chain that has already advanced several blocks by the time each response arrives. These are not edge cases. They are the baseline operating conditions for any application built to take full advantage of MegaETH’s speed.
This is why raw TPS is a misleading starting point for capacity planning. A more useful frame is request multiplication: for every transaction your application processes, how many RPC calls does it generate, and at what frequency? On slower chains that ratio is forgiving enough that most providers absorb it without issue. On MegaETH it gets large fast, and the provider’s ability to sustain that load without rate limiting, increased latency, or dropped subscriptions becomes the real constraint.
| Ethereum Mainnet | MegaETH (EVM blocks) | MegaETH (mini-blocks) | |
| Block interval | ~12 seconds | ~1 second | ~10 milliseconds |
| Blocks per minute | ~5 | ~60 | ~6,000 |
newHeads events per minute | ~5 | ~60 | ~6,000 |
| Poll frequency needed to stay current | once per 12s | once per second | 100x per second |
| Confirmation tracking round trips | low | moderate | very high |
The Realtime API: MegaETH’s hidden unlock
On a standard EVM chain, the transaction confirmation flow is a two-step process. You submit a transaction with eth_sendRawTransaction, get a transaction hash back, and then poll eth_getTransactionReceipt in a loop until the receipt appears. On Ethereum mainnet, where blocks arrive every 12 seconds, this is tolerable. On MegaETH, where a transaction is packaged into a mini-block within 10 milliseconds of arrival, the polling loop becomes the bottleneck. You are introducing artificial latency into a system specifically engineered to eliminate it.
MegaETH’s Realtime API addresses this directly. The key method is realtime_sendRawTransaction, which submits a transaction and blocks until the receipt is available, returning it in a single round-trip. No polling, no receipt loop, no managing the gap between submission and confirmation. The sequencer processes the transaction, packages it into a mini-block, and the method returns with the full receipt. The entire flow collapses from two steps into one.
const { ethers } = require("ethers");
const provider = new ethers.JsonRpcProvider("YOUR_CHAINSTACK_ENDPOINT");
const wallet = new ethers.Wallet("YOUR_PRIVATE_KEY", provider);
async function sendWithRealtime() {
const tx = await wallet.populateTransaction({
to: "0xRecipientAddress",
value: ethers.parseEther("0.01"),
});
const signedTx = await wallet.signTransaction(tx);
// Single call returns the receipt directly -- no polling required
const receipt = await provider.send("realtime_sendRawTransaction", [signedTx]);
console.log("Confirmed in mini-block:", receipt.blockNumber);
console.log("Gas used:", receipt.gasUsed);
}
sendWithRealtime();The Realtime API also extends eth_subscribe to expose mini-block level events. Subscribing to miniBlocks over WebSocket delivers each mini-block’s full set of transactions, receipts, and state changes as soon as it is produced, rather than waiting for the next EVM block to be sealed.
const { WebSocket } = require("ws");
const ws = new WebSocket("YOUR_CHAINSTACK_WSS_ENDPOINT");
ws.on("open", () => {
ws.send(JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "eth_subscribe",
params: ["miniBlocks"],
}));
});
ws.on("message", (data) => {
const message = JSON.parse(data);
if (message.method === "eth_subscription") {
const miniBlock = message.params.result;
console.log("Mini-block number:", miniBlock.mini_block_number);
console.log("Transactions:", miniBlock.transactions.length);
console.log("Timestamp (microseconds):", miniBlock.mini_block_timestamp);
}
});There is also eth_callAfter, which solves a specific problem that comes up frequently in DeFi workflows. If you send an approval transaction and then immediately want to simulate the follow-up swap, a standard eth_call might execute before the approval has been confirmed, producing a misleading result. eth_callAfter waits until the sender’s nonce reaches a target value before executing the call, eliminating the race condition entirely.
What makes the Realtime API the first thing to check when evaluating any provider is that it is not part of the standard Ethereum JSON-RPC specification. Providers have to explicitly implement it, and many have not. Chainstack documents Realtime API support for MegaETH, but regardless of which provider you use, confirming this before you build is not optional. A provider that only exposes eth_sendRawTransaction is not wrong, but it is leaving MegaETH’s core speed advantage unreachable. Any application built around confirmation latency, real-time event delivery, or dependent transaction flows will be running at a fraction of what the chain can actually offer.
RPC on MegaETH: where standard assumptions break
Moving to MegaETH with an Ethereum mindset will break your application in three specific places, and none of them are obvious until something goes wrong in production.
newHeads subscriptions
A provider can pass every standard compliance check and still silently cap your application at 1-second block resolution if it only exposes newHeads at the EVM block level rather than the mini-block level. Your event-driven logic fires, your code looks correct, but the 10ms advantage the chain was built for never reaches your application.
Gas estimation
MegaETH’s multidimensional gas model means local simulation through Hardhat or Foundry will frequently undercount gas, producing “intrinsic gas too low” errors in production that never appeared in testing. Gas estimation has to go through eth_estimateGas on the RPC itself, not local tooling.
Debug and trace access
MegaETH’s public endpoint does not expose debug_* or trace_* methods. Teams building transaction simulators, analytics pipelines, or operational tooling that depends on execution traces will hit a wall on public infrastructure and need a managed provider that explicitly documents debug and trace coverage for MegaETH.
What makes these failure modes particularly costly is that none of them announce themselves clearly. A newHeads subscription works, gas transactions go through most of the time, and the public RPC responds correctly to standard calls. The degradation is silent. Your application runs, but it runs slower than it should, fails under load it should handle, or simply cannot support the use cases you are building toward. On a slower chain, the gap between a good provider and a mediocre one is a performance difference. On MegaETH, it is a product difference.
Choosing infrastructure for production
Supporting MegaETH and handling MegaETH well are not the same thing. A provider that lists MegaETH in its supported chains has cleared a low bar. What actually matters for production is a narrower set of questions: does it expose mini-block subscriptions, does it support realtime_sendRawTransaction, does it offer full debug_* and trace_* coverage, and can it sustain the request volume that a 10ms block chain generates without rate limiting or latency degradation?
Shared infrastructure is a reasonable starting point but it has a ceiling. On slower chains, shared RPC can carry production workloads indefinitely because the request volume stays manageable. On MegaETH, a high-throughput application, a trading bot running confirmation loops, a game backend tracking state on every mini-block, or a consumer app spiking during a viral moment, will eventually saturate shared infrastructure in ways that are hard to predict and harder to debug. Dedicated nodes remove that ceiling. They give you isolated compute, predictable latency, and the ability to run sustained burst traffic without competing against other tenants. The right time to move is before you need to.
Pricing model is also worth thinking through carefully at this scale. Credit and compute unit models that work fine on Ethereum become difficult to forecast on MegaETH because request volume is so much higher. A method-weighted pricing model that charges differently for eth_call, debug_traceTransaction, and standard reads can produce bills that are genuinely hard to predict when you are generating hundreds of requests per second. Flat-rate or request-unit models are easier to budget against at high throughput. The predictability of the pricing structure matters almost as much as the headline price.
| Criteria | What to check |
|---|---|
| Mini-block | Provider exposes miniBlocks via WebSocket, not just newHeads at EVM block level |
| Realtime API support | Provider implements realtime_sendRawTransaction and eth_callAfter, not just standard eth_sendRawTransaction |
| Debug and trace access | Provider explicitly documents debug_* and trace_* method coverage for MegaETH |
| Gas estimation | Provider supports eth_estimateGas correctly against MegaETH’s multidimensional gas model |
| Throughput capacity | Provider can sustain 100+ requests per second without rate limiting, latency degradation, or dropped subscriptions |
| Infrastructure tier | Dedicated nodes available for production workloads, not just shared infrastructure |
| Pricing model | Flat-rate or request-unit pricing rather than method-weighted compute units, which become unpredictable at high request volumes |
Production readiness: what to get right before launch
MegaETH surfaces infrastructure problems as application bugs. A confirmation loop that polls every 500ms works fine on Ethereum and falls apart on a chain where the relevant mini-block has come and gone before the first poll fires. A WebSocket connection without reconnect logic survives occasional drops on a quiet chain and breaks under the sustained pressure of mini-block subscriptions. The monitoring signals that matter most before launch are p95 and p99 RPC latency rather than averages, WebSocket reconnect frequency as a direct measure of subscription stability, 429 response rates as an early warning on provider tier limits, and block lag as the clearest sign that your infrastructure is falling behind the chain.
The public MegaETH endpoint is the right place to start. It handles prototyping and contract validation well. The mistake is staying on it too long. Providers take time to evaluate, dedicated nodes take time to provision, and finding out your infrastructure cannot keep up during a traffic spike is a worse outcome than migrating early. Build on the public endpoint, but treat the move to managed infrastructure as part of the launch plan rather than something to figure out later.
Conclusion
MegaETH is genuinely new infrastructure. A different execution environment with different failure modes, different tooling requirements, and a different relationship between infrastructure quality and application capability. Treating it like a drop-in Ethereum replacement means leaving most of what it offers unreachable.
The developers who get the most out of it will be the ones who verify Realtime API support before committing to a provider, route gas estimation through the RPC rather than local tooling, and treat the move to dedicated infrastructure as part of the launch plan rather than an afterthought. Get started with MegaETH on Chainstack.
FAQ
Not entirely. Existing tooling works, but gas estimation and event subscriptions need to be updated — local simulation breaks, and newHeads subscriptions must expose mini-blocks to get full speed.
MegaETH uses a multidimensional gas model that local simulators don’t model correctly. Route all gas estimation through eth_estimateGas on the RPC instead.
Mini-blocks are produced every 10ms and carry transactions, receipts, and state changes. EVM blocks follow every second in standard Ethereum format. Every transaction appears in both.
Check explicitly in their documentation for realtime_sendRawTransaction and miniBlocks subscription support. If it’s not documented, assume it’s not supported.
Before launch, not after. Shared infrastructure has a ceiling on MegaETH — evaluate providers early, dedicated nodes take time to provision.
Track p95/p99 RPC latency, WebSocket reconnect frequency, 429 response rates, and block lag. Averages will hide problems that p99 makes visible.